
The Algorithmic Subjectivist Myth
Meehl's Philosophical Psychology, Lecture 9, part 2.

This post digs into Lecture 9 of Paul Meehl’s course “Philosophical Psychology.” Technically speaking, this lecture starts at minute 82 of Lecture 8. The video for Lecture 9 is here. Here’s the full table of contents of my blogging through the class.
While we can construct a calculus for Probability 1 with laws for manipulating logical formulas into mathematical inequalities about likelihoods, how do we actually assign probabilities to metalinguistic statements? Let me prime you with a few questions:
What is the probability that smoking causes cancer?
What is the probability that the theory of evolution is true?
What is the probability Bruno Hauptmann kidnapped the Lindbergh baby?
What is the probability of the Big Bang?
What is the probability of Freud’s Theory of Dreams?
These are all questions about theories based on accumulated evidence. None of these questions are about predictions about the future. Given Kolmogorov’s probability axioms, deductive logic, and a supercomputer, is there an algorithm that can take our current evidence and give us a number for each of these statements?
A popular way to extract probabilities from individuals is to goad them into betting. Meehl describes how his colleague James Boen skillfully extracted probabilities from students.1 Boen was a professor of Biometry and a dedicated Bayesian. He would start with something vague, like asking how much you’d be willing to bet on the existence of aliens (I want to believe). Then, he would propose bets of different sizes on other less controversial topics. How much would you bet that Nixon would flunk a lie detector test on Watergate? How does it compare to your willingness to wager on the existence of aliens? Like a skilled psychotherapist, he’d eventually break the will of the interrogated, getting them to say, “No, I wouldn’t take those odds.” This confession meant that the probability their brain had computed was lower.
Boen’s Betting Inquisition is an algorithm for measuring someone’s internal probabilities. In fact, measurement was precisely what Frank Ramsey had in mind when he conceived of subjective probability a century ago: “The old-established way of measuring a person's belief is to propose a bet, and see what are the lowest odds which he will accept.”
However, measuring a person’s beliefs doesn’t tell us how they came to those beliefs. Just because you can twist someone’s arm into betting doesn’t mean that the person arrived at their comparative belief system by some well-specified algorithm. Meehl claims there is no algorithm to compute these probabilities. There is no algorithm to convert evidence into belief.
I can hear the Bayesians coming for me already. But let me make Meehl’s case. In his Appraising and Amending Theories paper, Meehl has this elucidating diagram illustrating the disconnect between statistics and theories.

The map from substantive theory T to testable statistical hypothesis H goes through a derivation chain involving auxiliary theories, instruments, ceteris paribus assertions, and experimental conditions. The map from hypothesis to observation is through the statistical model manufactured by the derivation chain.
Statistical theory provides a variety of means to infer the veracity of H from O. Usually this goes through Bayes’ Rule.
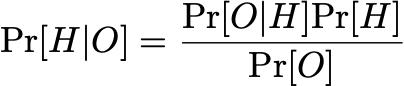
When we perform statistical inference, we attempt to calculate the left-hand side. It is the probability the statistical hypothesis is true given the observed experimental data. The right-hand side has terms we can hopefully compute. Pr[O|H] is the probability of the observation given the statistical hypothesis and is what we derived from our theory. Pr[H] is our pre-existing belief in H (our prior). We can compute Pr[O] if we know the probability of the observation when the statistical hypothesis is not true: Pr[O | not H]. More often than not, this “not H” is what people call their null hypothesis.
This seems all well and good. But let’s say we now infer that H has high probability given all of our evidence. Then what? We cared about T! How do we compute the probability of T from O?
Let me give a simple example using a preposterous correlation from a prior lecture. I have a complex theory that asserts that sunscreen use causes juvenile delinquency I use a theoretical derivation chain that deduces a model where the odds of delinquency increase exponentially with regular sunscreen use.
With my model in hand, I want to test it. I gather some data on children, put together a big CSV file, and run logistic regression with my favorite statistical software package. The software tells me that the probability of seeing the data given equal in both groups is less than 5%. It also reports the confidence interval only contains exponential functions that increase with sunscreen use. That’s all that logistic regression does, by the way. All of these steps, from the data to the confidence interval and p-value, are algorithmic.
I could proceed to do other calculations to squeeze out a posterior distribution on the parameters of the exponential function. This posterior tells me the probability of the parameter of my logistic model given the data… assuming the data was generated from a logistic model. Again, my friends, question-begging. What does this tell me about the derivation chain? About the different mechanisms I proposed that lead from sunscreen to delinquency? Can I conclude that sunscreen use increases the risk of delinquency?
Well, no. Because now we need to do a Lakatosian defense. There is a Pr[H | T] that we need to sort through. How does the statistical model derive from the theory, auxiliaries, ceteris paribus clause, and experimental conditions? I imagine you could develop a very clean, logical chain of statements that precisely deduces H from T. If you did this, you could apply Bayes’ Rule again to get some functional form for Pr[T | H]. This functional form would depend on a bunch of other probabilities that you’d need to sus out from the chain. What is the probability of the hypothesis if we keep everything fixed but negate one auxiliary? What about if we negate only the ceteris paribus clause? What does that even mean? What would the probability be under the negation of the experimental conditions? There’s a combinatorial explosion of probabilities you’d need to write down. And then, you’d need a prior probability on every step of that chain too. What’s the prior probability that the ceteris paribus clause is true? 0%? Bayesian philosophers have been trying to work out the details of such inferences for decades, but no one has gotten anywhere satisfactory. Even when there is only a single auxiliary theory!
Regardless, science has advanced despite our inability to algorithmically quantify the probabilities of theories. We’ve had a quasi-functional legal system despite asking jurors to estimate if defendants are guilty with a probability greater than 50%. Our heuristic probability and inference systems are fallible, but they work pretty well, all things considered.
Everything I wrote about today was about the difficulty of inferring the probability of things that had already happened. What about estimating things that haven’t happened yet? That doesn’t sound easier to me! But people love to bet, I suppose. I’ll grant the gamblers and superforecasters this: predicting the future at least gives us consistent opportunities to see how often we’re wrong. In the last post on Lecture 9, I’ll discuss how this ability to guess and check provides our connections between Probability 1 and Probability 2.
In the Lecture, Meehl refers to Boen simply as “Boen from Biometry.” I couldn’t figure out who this was from context and came up short doing web searches. Thanks to reader Zach Meisel for identifying Boen.
Yeah, I am 100% with Meehl that there is no algorithm for converting vibes to probabilities. But there is an algorithm for revising the already given probabilities, and it relies on de Finetti's ideas of coherence (which can be reconciled with Kolmogorov's axioms: https://www.sciencedirect.com/science/article/pii/S0167715203003572). I like to think of the requirements of coherence as a potential field that enforces global constraints by exerting forces on local, possibly incoherent, probability assessments.
Here's my take on these issues
Grant, S., A. Guerdjikova, and J. Quiggin. 2020. Ambiguity and Awareness: A Coherent Multiple Priors Model. The B.E. Journal of Theoretical Economics 0
Ambiguity in the ordinary language sense means that available information is open to multiple interpretations. We model this by assuming that individuals are unaware of some possibilities relevant to the outcome of their decisions and that multiple probabilities may arise over an individual’s subjective state space depending on which of these possibilities are realized. We formalize a notion of <jats:italic>coherent</jats:italic> multiple priors and derive a representation result that with full awareness corresponds to the usual unique (Bayesian) prior but with less than full awareness generates multiple priors. When information is received with no change in awareness, each element of the set of priors is updated in the standard Bayesian fashion (that is, full Bayesian updating). An increase in awareness, however, leads to an expansion of the individual’s subjective state and (in general) a contraction in the set of priors under consideration.