
Crud
Meehl's Philosophical Psychology, Lecture 6, part 6.

This post digs into Lecture 6 of Paul Meehl’s course “Philosophical Psychology.” You can watch the video here. Here’s the full table of contents of my blogging through the class.
The most glaring issue with null hypothesis testing in observational studies, one that critics like Meehl have been arguing since at least the 1960s, is that the null hypothesis is almost always literally false.
“Even things that are not of any theoretical interest to us are not likely to be totally independent of one another. It is almost impossible to come by a Pearson r of zero point zero zero. In psychology, you really would have to work at it.”
Note again, Meehl is talking about studies where you compare factors that people bring with them.1 Meehl gives the example of probing the statistical significance of the difference between boys’ and girls’ ability to name colors. He goes through a long description of why it’s preposterous to assume that a collection of boys would have exactly the same expected ability as a collection of girls.
In the social and biological sciences, the null hypothesis is never true because everything is correlated with everything else. The question is just how much. Meehl worries that everything is highly correlated with everything else.
Meehl calls the ambient correlation between variables the crud factor. In the class and in his writing, he’s never totally precise about what the crud factor is, but it seems pretty clear from context that he is talking about the average value of the Pearson r, also known as the Pearson correlation coefficient. The Pearson r is a normalized measure of the covariance between two random variables:
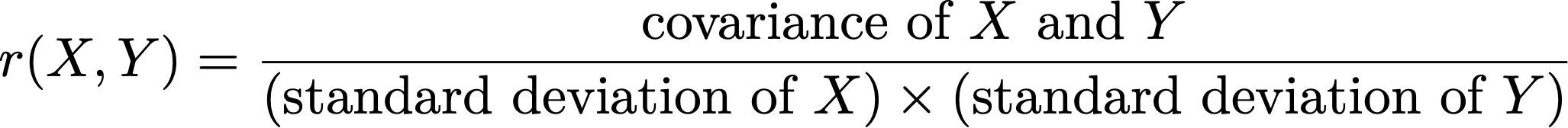
Pearson’s r is also called the correlation coefficient. It conveniently takes values between -1 and 1. The crud factor is the mean of all of these correlation coefficients over all possible pairings. How large is it? And how large does it need to be in order to imperil the paradigm of hypothesis testing? It’s going to take me over a week to go through why this particular variable is a good one, that it’s probably quite large, and why it means that “large N” studies are almost always false.
Let me start with the evidence that the crud factor is large. Meehl describes some surprising results he found with David Lykken. They looked at a survey of 57,000 high school seniors administered by the University of Minnesota Student Counseling Bureau's Statewide Testing Program in 1966. The survey asked a bunch of questions about their families, their preferred vocations, their experience in school, their hobbies, and so on. Meehl lists some of the questions:
What magazines do you take in the home?
What are your plans to go on to college, if any?
What are you going to major in?
How often do you go out on dates?
Do you like picnics?
Which shop courses did you prefer? Sheet metal, electricity, printing, etc.
What religious views do you adhere to?
Meehl and Lykken computed the correlation coefficients of 44 different questions, leading to 946 correlations. Of these, 94% were significant at 0.1 level. Most were significant at 0.0001 level.
If everything tests significant, you can justify almost any psychological just-so story with a significance test. For example, for the last question, there was a breakdown into the varied denominations of Lutherans, asking whether a student was from the ELC, LCA, Missouri, or Wisconsin synods. What shop class a boy preferred in high school was correlated with which Lutheran synod a boy belonged to. Meehl launches into some satirical theorizing:
“The Missouri synod came over here in 1848, mostly fleeing from the unsuccessful revolutions of 48 in Germany. They were, to some considerable extent, skilled workers. High-level proletariat. Tinsmiths and factory workers with a strong socialist leaning. So maybe they had genes and environment leaning more toward things like sheet metal and electricity. Whereas the LCA or the ALC were mostly, like my ancestors, Norwegian yokels that came over here not from a revolution but because they heard there was good soil and they didn't like the established Lutheran Church of Norway or Sweden. So they came over here, and they were farmers and foresters Lumberjacks. The view was in the early days of Minnesota that a dumb Swede was good for nothing except to be a farmer or to chop trees down. Maybe they're better at woodwork.”
Bam. Publish it! Meehl then asks whether being in the Missouri synod would ever lead to you liking printing. He first tells the class that this would be absurd but has a sudden eureka moment and exclaims. “Wait Wait, I can do that one!”
“The Missouri Synod was the most scholarly of the bunch. All of the clergy that I knew when I was in that outfit had four years of Hebrew, four years of German, four years of Latin, and of course Greek… [They had a] very strong emphasis upon scholarship and upon intellect, whereas some of the Scandinavian Lutheran's were a little bit like Saint Bernard, you know, that you shouldn't have too much [G-factor] cooking here.”
Meehl’s assertion, which we all know is true, is that a clever theoretician can spin a story for any large correlation plopped before them. It would probably be impossible for them to explain the entire universe of correlations, but the scientific literature doesn’t require that. Organic diet is correlated with lower cancer rates? Nice! Send it to JAMA!
If everything is correlated with everything, the question remains how much? Meehl thinks it’s enough to worry about, but he’s not sure how to estimate it more generally. In Lecture 7, he describes a few more studies where people found shockingly large crud factors. He ponders
“I don't know how big the average correlation is between any pair of variables picked at random out of a pot. Somebody should study that.”
Well, somebody did! I haven’t yet done an exhaustive survey, but I did do some preliminary googling for the crud factor and quickly found several studies. Ferguson and Heene correlated 14 variables they considered to have “little significance” with adolescent aggression and found “significant” correlation coefficients that were near 0.1 in many cases. Frequency of sunscreen use was highly correlated with adolescent delinquency.
In another study, blogged about here, Webster and Starbuck did an analysis of 15,000 correlations published in the Administrative Science Quarterly, the Academy of Management Journal, and the Journal of Applied Psychology. They found a distribution of correlations that looks like this:

The mean is about 0.1, showing that the crud factor is definitely nonzero. But what I found most fascinating is that the standard deviation is huge. It’s somewhere in the range of 0.2 to 0.3.
Webster and Starbuck’s plot made me realize that we need to go a step beyond Meehl. An ambient crud factor is bad, but having a highly variable crud distribution might be worse. Null Hypothesis Testing would be problematic even if the crud factor (i.e., the average correlation) equaled zero. Aligned with Meehl’s thought experiment about variables picked out of a pot, let me define the crud distribution as the distribution of the correlation coefficients of randomly selected pairs of variables. What if the mean of the crud distribution was zero, but the standard deviation was 0.2? That wouldn’t be good either! It would mean that the probability of picking two variables at random and finding a correlation coefficient of 0.25 or more is over 20%. As I’ll show in the next post, a crud distribution with nontrivial variance is just as worrying as a large crud factor.
I can certainly construct randomized experiments in which the null hypothesis is probably true. If I take a cohort of people and assign them at random to two identical treatments, the null hypothesis will be true. Maybe I take two bottles of Advil from the same pharmacy and give the treatment group pills from the first bottle and the control group pills from the second. In RCTs, the null hypothesis might be true. But randomized experiments have their own issues, which I’ll come back to later.
I would be interested to see an experiment of the following form:
Pick a bunch of things from the pot of crud correlations.
Give them to theoreticians. Tell the theoreticians whatever things they got are strongly correlates (even if they are actually inversely correlated).
Have the theoreticians come up with an explanation for whatever things they were given.
Have other people rate the explanations the theoreticians come up with.
Are the explanations for things with actually positive correlations rated as being better than the explanations for things with secretly negative correlations?
All good points: This situation calls for a more global analysis that looks simultaneously at all of these correlations to find the causal factors. Has anyone attempted that?
Regarding the truth or falsity of H0: Perhaps it would be better if H0 were called a "reference hypothesis"? Statistics is fundamentally about whether data has the power to resolve differences among multiple reference hypotheses. It seems to me that asking for any hypothesis to be "true" is fundamental misguided, and this is one of the ontological flaws of the Bayesian approach.