
Prompts for Open Problems
A few research problems the class inspired me to think about

This is a live blog of the final lecture of the 2025 edition of my graduate machine learning class “Patterns, Predictions, and Actions.” A full Table of Contents is here. I tried to summarize my semester reflections in class on Thursday, but found my thoughts haven’t quite settled yet. I’m hoping a week of posting will help me sort through it.
I don’t think I need to write a post arguing for more machine learning research. We definitely have more than we need. Rather than asking for more research, I’m proposing perhaps different research. I got myself interested in a bunch of problems while teaching the class, so let me take a post to selfishly nudge you in the directions that interested me. There are always questions and more experiments to be done.
Design-based Machine Learning
Abandoning the myth of data-generating distributions is more than just semantic. Nuances emerge when you treat all randomness as generated by the engineer rather than by nature. In statistics, this is the contrast between the model-based (natural randomness) and design-based (intentional randomness) views of statistical inference.
I remain skeptical of statistical inference, but I think there is a promising way to extend the online-learning regret view of decision making to develop a more compelling version of Neyman-Pearson decision theory.
I was surprised to see how much of machine learning can be cast in a design-based frame. I just had to gently rearrange some of the definitions and verify that the probability bounds held for without-replacement sampling (they usually do). This design-based perspective opened the door to novel and interesting analyses. For example, the adaptive experiment design I covered in Lecture 19 shows how to formulate decision theory at the population level and results in a simple adaptive algorithm for sequential experiments without power calculations. It also indicates that all current studies are woefully underpowered if we actually cared about population-level outcomes. (80% power only suffices when your population has five people).
Design-based bounds for more complex models might provide a better understanding of trade-offs in algorithmic decision systems that make predictions from data. A design-based perspective might change how we use machine learning to design such complex algorithmic decision aids.
A theory of competitive testing
I still think the most frustrating thing about machine learning theory is that we have no consensus explanation for plots like this one:
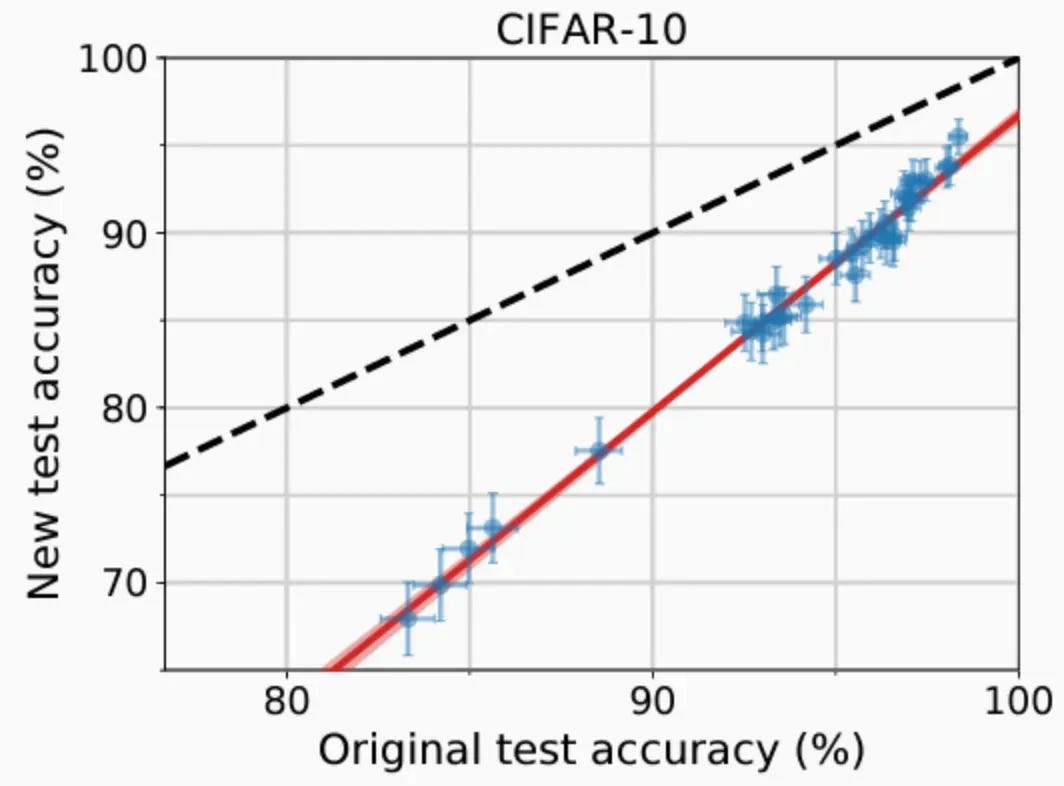
This is from Lecture 14. It is a strikingly robust phenomenon. It’s been reproduced in hundreds of benchmarks. It drives much of the “large models are all you need” discourse. And yet, all of our consensus theories predict that these plots should look different.
Alexandre Passos suggested in the comments that machine learning theory had moved from treating things like math to treating things like physics. We find some robust linear trends when we throw scatter plots on the same axes. But plots alone are not sufficient to transform observational science into physics. There’s a group of theoretical physicists, the phenomenologists, who cook up models to explain these trends. They aren’t always successful, but they love to put out theories. And sometimes interesting new physics comes from this spitballing.
I realize this 10 year old problem is now boring. It’s sexier to pose theories about world models or LLM skill acquisition or the optimal noise schedules for diffusion models. But competitive testing is the core of our field, and it’s embarrassing that we don’t have any reasonable explanation for how it works.
Beyond average case evaluation
A recurring theme in the class was metrical determinism. Once you decide that you will evaluate your performance by the average on some population, you’re stuck with statistical methods, and probably can’t beat competitive testing on train-test benchmarks. I always wonder whether this is really the only way to think about evaluation. Why can’t we escape bean counting? This question is likely more sociological than mathematical, and I may need a whole blog post to make it well-posed. I’ll add it to my to-do list.
Certainty equivalence in LLM reasoning
Cleaning up LLM reasoning may be the lowest-hanging fruit on this list. Right now, “reasoning” in LLMs means applying policy gradient to increase the probability that LLMs will answer test questions correctly. I’m not convinced that I want to run a bunch of experiments to get LLMs to do well on math tests, but all of my experience is screaming at me that policy gradient is leaving a ton of efficiency on the table. These optimization methods are just trying to take a model that gets 20s on tests to a model that gets 90s on tests. That is, we need optimizers for the endgame, not for the cold start of the optimization algorithm. In optimization, the end game is almost always the fast and easy part. I’m sure there are straightforward innovations to achieve the same level of performance as the XPO methods in a fraction of the time. Every time I have looked at a policy gradient method, this has been the case! I’ve seen no evidence to the contrary that this time is different. If you are an intrepid optimization researcher who wants to run experiments on this problem and want a grumpy advisor who doesn’t even want to be a coauthor, please send me a note.
Open source, Open corpus language models
Perhaps the way you could get me to care more about RL in LLMs is that they might help in the quest to build high-performing, open-source, open-corpus large language models. This topic didn’t come up in the class at all, but I’m plugging it here as I still think it’s the most important “open problem” in applied machine learning. Many teams have been making progress on this front, be they at Allen AI, Pleais in France, or pockets of Andrej Karpathy’s free time. I think that now we know what we “want” from LLMs, better algorithmic innovations can get us there for considerably less computing resources. Endless research and commercial possibilities open up once you can train a model on a single workstation. Moreover, breaking the current narrative that the “bitter lesson” means covering the earth with GPUs would be better for our geopolitics.
I think this is doable. There just needs to be a will to do it.
I love the revised cifar plot and I think about it a lot.
One dumb phenomenological way of thinking about curves like that is assume we can predict the pass rate of a model from two factors: an intrinsic model capability and an intrinsic problem difficulty. Then if you assume a dumb P(model on problem) = sigmoid(capability - difficulty) and if you approximate the sigmoid with a linear function you should get this type of behavior where as you look at the ensemble of models on a fixed problem set you'll see a line, and switching problem sets the line will have different slopes all meeting at 100% accuracy. This doesn't explain why the revised cifar is reliably harder than the original cifar, however. But it does explain behavior I've seen in LLMs where broadly speaking a large number of unrelated benchmarks evaluated over many models have a PCA of surprisingly low dimension, and so you're better off picking a small number of metrics to look at and ignoring the rest.
I think this is how IQ was first defined?
That said I still cannot explain why the new line is lower than the old line.
In ecology, our model often has two parts: an observation model and a biological model. For example, in species distribution models, we want to know whether a particular location (described by a vector of "habitat covariates") is occupied by a particular species. This could be viewed as a simple classification problem: f(habitat) = P(occupied | habitat)}. However, our observations are made by humans who visit the location and spend some amount of effort looking to see if the site is occupied. The probability that they will detect the species given that the site is occupied depends on a set of observation covariates that may include some habitat covariates (density of shrubs) as well as covariates for effort and weather (and possibly, degree of observer skill). g(obscovariates) = P(detection | site is occupied). The likelihood function is therefore something like P(detection | site is occupied) * P(occupied | habitat). This is known as the Occupancy Model, and we need to estimate the parameters of both f and g from the data. This estimation is quite delicate, because there are trivial solutions (e.g, all sites are occupied, and all negative observations are due to low detection probability; or detection probability is 1.0 and all negative observations are due to bad habitat).
Two questions: First, is it useful to view this as an extension of your "design-based ML" to include a measurement model? Second, I suspect that most ML analyses should include an explicit measurement model. We are accustomed to just dumping all of the covariates into a system and estimating h(obscovariate, habitatcovariates), but this loses the causal structure of the observation process.