
Correlation Is All We Have
Meehl's Philosophical Psychology, Lecture 6, part 7/7.

This post digs into Lecture 6 of Paul Meehl’s course “Philosophical Psychology.” You can watch the video here. Here’s the full table of contents of my blogging through the class.
To understand why the crud factor is a major problem, it’s worth unpacking how hypothesis tests, though the foundation of causal inference, are always about correlation.
Let’s focus on the most standard hypothesis tests that attempt to estimate whether some outcome is larger on average in one group versus another. Meehl used the example of comparing the difference in color naming aptitude between boys and girls. I worked through an example last week comparing the effectiveness of a vaccine to a placebo. Almost all hypothesis tests work by computing the difference, D, between the means of the outcomes in each group. Since the groups are always samples of a population, the computed difference on the sample is only an estimate of the difference in the broader population. We thus also compute an estimate of the standard error, SE, which is the standard deviation of this mean difference. This gives us a sense of the precision of our difference estimate.
To test statistical significance, we compute the probability under the null hypothesis that the population’s mean difference was literally zero, but, due to the standard error, we would have seen a sampled mean difference at least as large as the one we computed. Ugh, what a silly and confusing convention! But bear with me. In a few paragraphs, you will know what this is really doing and why it’s not only annoying but also pernicious.
The probability of seeing such a sampled difference under the null hypothesis is the probability of seeing a value of size D/SE or larger when taking a sample from a normal distribution with mean zero and variance 1. The quantity D/SE is all we need to compute the p-value and test statistical significance. The ratio D/SE hence gets a special name: the z-score. The z-score is always the estimated mean difference divided by the estimated standard error. If it is greater than 2, then the finding is statistically significant. That’s because 95% of the normal distribution is within two standard deviations of the mean.
Now, that’s the motivation for the z-score. I hope it’s clear that there is nothing particularly rigorous about this methodology. I reminded us yesterday that the null hypothesis–that the mean difference equals zero—is never literally true. But it’s also never literally true that the mean difference is normally distributed. I also can never figure out why we should care whether a probability is small under the null hypothesis. And then what? No one has ever explained to me what you do with this information. As Gerd Gigerenzer likes to remind us, null hypothesis significance testing (NHST) is just a mindless ritual.
Let me give you a different interpretation of NHST that I think might be more intuitive but also raises more concern about the whole enterprise. Let me introduce two new variables: Y is the outcome we want to compare between groups. X is a binary variable equal to 0 if the individual is in group A and equal to 1 if the individual is in group B. Let’s say you have a sample of n pairs of (X,Y). The mean of group A is then
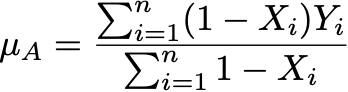
This identity is true because when Xi is 0, (1-Xi) equals 1. So the numerator is summing up the Y values when X equals 0, the denominator is counting the number of times X equals zero. Similarly, the mean of group B is

With my notation, if you do a little algebra, it turns out that the z-score takes a simple form:
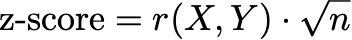
In words: the z-score is the Pearson correlation between X and Y times the square root of n.1 So when you ritually NHST, all you are doing is seeing whether the Pearson r of the treatment and outcome variables is greater than 2 over root n. That’s it.
I want to emphasize that my formula for the z-score is true even in randomized controlled trials! RCTs, it turns out, are also only about correlation. But because we explicitly randomize the X variable, we know that correlation is measuring the effect of causation. We’re not proving that X causes Y in an RCT. We’re measuring the size of the influence of X on Y knowing there is already some causal connection between the two. Correlation doesn’t imply causation, but it’s the only thing we can measure with statistics.
OK, but now it should be crystal clear why the NHST framework is an annoyingly obfuscatory convention and also why the crud factor is a huge problem. If you have two weakly correlated variables X and Y, you’ll find a statistically significant result with a large enough sample. Two things can bring us to statistical significance: Either the treatment and the outcome are highly correlated OR n is large. When n is small, you are “underpowered” insofar as you’ll fail to reject the null hypothesis even though X and Y are strongly correlated. But when n is moderately sized, you will reject the null hypothesis for weakly correlated variables.
Let’s come back to the crud factor and crud distribution. I’m going to be a bit more precise about crud today. Given a population of variables, the crud distribution is the distribution of the Pearson correlation coefficients between all pairs in the population when the pairs are chosen uniformly at random. Following the suggestion of Matt Hoffman and Jordan Ellenberg, the crud factor is the average magnitude of the Pearson r. In the example yesterday from Webster and Starbuck, the crud distribution was approximately Gaussian with mean 0.1 and standard deviation 0.2. The crud factor of this distribution is 0.2.
Now let’s imagine Meehl’s silly thought experiment from the end of Lecture 6: I have a pot of binary treatments, I have a pot of outcomes, I have a pot of theories. I pick out one thing from each pot at random. A theory T, a treatment X, and an outcome Y. I then assert T implies that X causes Y, even though there is no connection here between the logical content of the theory and the relationship between treatment and outcome. Then I gather a sample and test for significance.
What happens in the presence of a crud distribution? Let’s use the rough numbers from Webster and Starbuck as parameters for the crud distribution. If I gather a cohort of 800 participants, then the probability of rejecting the null at 0.05 is over 75%. For two variables I chose at random, the probability of finding a statistically significant result is 3 in 4. You might say, well, maybe we could fix this by setting the p-value threshold lower. Say to 0.001? At this p-value threshold, the probability of finding a statistically significant result between randomly chosen variables is over 60%. Even with a 5-9s p-value threshold (rejecting if p<10-5), the chance of rejecting the null for a nonsensical comparison is over 50%.
We find ourselves in the midst of yet another statistical paradox. If I sufficiently “power” a study that looks at relationships between randomly chosen attributes, and if the crud factor is not negligible, then I can corroborate theories that have no connection with facts. And the corroboration only increases if I make n larger. Oh crud!
I’ve never seen the z-score written this way before. If you’ve seen this formula in print, could you please send me a reference? And if you haven’t seen this identity before, are you as outraged as I am about how we teach hypothesis testing?
I like to mentally find-and-replace phrases like "we cannot reject the null hypothesis" with "man, we can't even reject the null hypothesis", which emphasizes both that rejecting the null is a pretty low bar if you've got a decent sample size and that NHST results are mostly just shorthands.
Unfortunately I have no such trick for making phrases like "the difference was highly significant" palatable, which is of course the real problem.
I read this post a while ago, but it came back to my mind when I was trying to push ChatGPT's o1 model to derive a relationship between the z-score in null hypothesis testing and a correlation measure. It succeeded in doing so, pointing out to a tradition in statistical behavioral research of relating the point-biserial correlation and the t-test coefficients. You asked for pointers of where the formula you've derived appears in print, but I struggled to find it. Rosenthal and Rosnow 2008 (https://scholarshare.temple.edu/handle/20.500.12613/79) show in equation 2.2 a formula relating t-statistics and the point-biserial correlation that seems to be well known in their community. This formula should approximate yours for large sample sizes