
To do the mindblowing
The first of four semester reflections

Let me close out the semester with a few reflections. I have four blogs planned. I’ll describe the high-level points I think we should take away from the class. I’ll break this into two parts. Today, I’ll work through the takeaways from the half-semester on Prediction, tomorrow from the half-semester on Actions. After this, I’m going to write a bit about pedagogy and live-blogging a class. I have thoughts! Finally, I’ll let you know what I plan to do next this substack.
So what can we say about Predictions? Or perhaps, what are the main points that I want you, my dear reader, to take away? There is a core to machine learning that we have known since the 1960s. This core is what made Rosenblatt’s perceptron work in the 1950s. And it’s what makes GPT4 work today.
We need a clearly defined goal for the task. We need a good dataset. We split this dataset into training and testing sets. We need reasonable means to represent prediction functions on the data. Then, and only then, we run gradient descent to build a prediction machine. Let’s dig in a bit to each of the components.
Goals. A well-defined prediction goal is critical. What exactly are we trying to predict? What does it mean for us to predict it correctly? How should we score bad predictions? A clear formulation of the goal gives us a metric that we can evaluate and minimize on datasets. The goal tells us what sorts of data we’ll need to collect. And it creates a competitive benchmark for researchers to compare their results.
Data. What defines machine learning is predictions from data. And better data sets lead to better predictions. We learn this lesson time and time again. Our latest lesson is that if you use the internet as your dataset, you can get miraculous demonstrations convincing people that a digital messiah has arrived.
The data fetish has certainly gotten too extreme over the past decade. Relying on terascale datasets makes it seem like the only people who can make predictions are those willing to burn billions of dollars and trees to run giant cloud computing centers. This perspective is valuable to our tech oligarchs, but it’s also nonsense.
Most tasks would benefit from thinking rather than mindlessly downloading the internet. Character recognition, one of the earliest tasks in machine learning, ended up working very well with only a few thousand supervised examples. There’s nothing wrong with adding engineering to make your prediction task easier. Working on designs that require less data is in everyone’s interest, and we have consistently seen evidence that less data is possible once people think about their problems. I hope another takeaway from this class is that there’s nothing wrong with thinking.
Train-test split. The holdout method is our core means of establishing the internal validity of prediction tasks. We split our dataset into a training set and a test set. We torture our training set with all sorts of potential prediction functions, and then we evaluate the best candidates on the test set. This procedure feels so simple and obvious, but as I’ve described, it was not at all obvious to the early machine learning engineers.
That the Holdout Method works follows from advanced but standard statistics. You can prove it works knowing only Hoeffding’s Inequality and the Union Bound, two inequalities you would learn in an advanced undergraduate course on probability. Though Learning Theory leans on far heavier statistical machinery, I don’t think you need to learn any of that in a general machine learning class. Understanding the basic idea behind the Holdout Method is enough.
I’d go as far as to say that the train-test split is one of the only parts of Generalization Theory I believe in. It works far better than the statistical theory tells us it should. And good train-test splits with clear goals lead to the frictionless competitive testing that has been the central force advancing the field.
Representation. At some point, you need to figure out how to transform your raw, digitized data into a prediction. There are so many choices for what’s possible here, and understanding signal processing clarifies these choices. But as we’ve seen in reality, a slight touch of nonlinearity is all you need to represent remarkable complexity. Does it help to know signal processing better? The answer is maybe. I realize you don’t have to know what a convolution is to build a convolutional neural network. But signal processing and some of the rudiments of kernel methods are useful to get a sense of what your data might look like, how you can transform it to be more amenable to prediction, and how to explore the space of possible function architectures.
Optimization. At the end of the day, machine learning becomes an optimization problem. Our task is to find the model that gets the best score on our test set. Now, we solve this optimization problem through a complex social game of competitive testing. We spent some time on this sociology in class, and understanding its dynamics will help us be better engineers.
But most people consider “machine learning optimization” to be minimizing some loss function on the training data. What are the crucial points there? In general, optimization is a solid foundation for any data scientist, and I’d recommend you take at least one course on it. But in contemporary machine learning, everyone just does gradient descent, and so, in an ML class, you should learn gradient descent and why it works.
What makes gradient descent special is that proving it converges also proves it generalizes. This is why it’s such a critical part of the machine learning toolkit. I still don’t know how to best think about this or teach it—I’m working on it! We spent a few lectures looking at mistake bounds and regret bounds and saw that out-of-sample prediction followed from a few lines once you assumed out-of-sample prediction was possible. And we saw that this sort of argument could be applied much more broadly. The main idea behind gradient descent is also the idea behind the perceptron, the PID controller, adaptive filtering, and adaptive control. Even though I know this and can prove these connections mathematically, there’s something magical every time I type it out. I still don’t feel like I understand gradient descent and its universality.
I think that’s it! The machine learning stack is simple, but getting all of the parts to align is an art that needs practice and skill. Machine Learning is a weird subject, and our quest to make it rigorous has been a mixed bag. I worry that by adding formalism, we are just trying to convince ourselves we’re doing the right thing. But too often, the formalism causes us to forget we have no idea what we’re doing. I showed this Venn diagram on the first and last day of class.
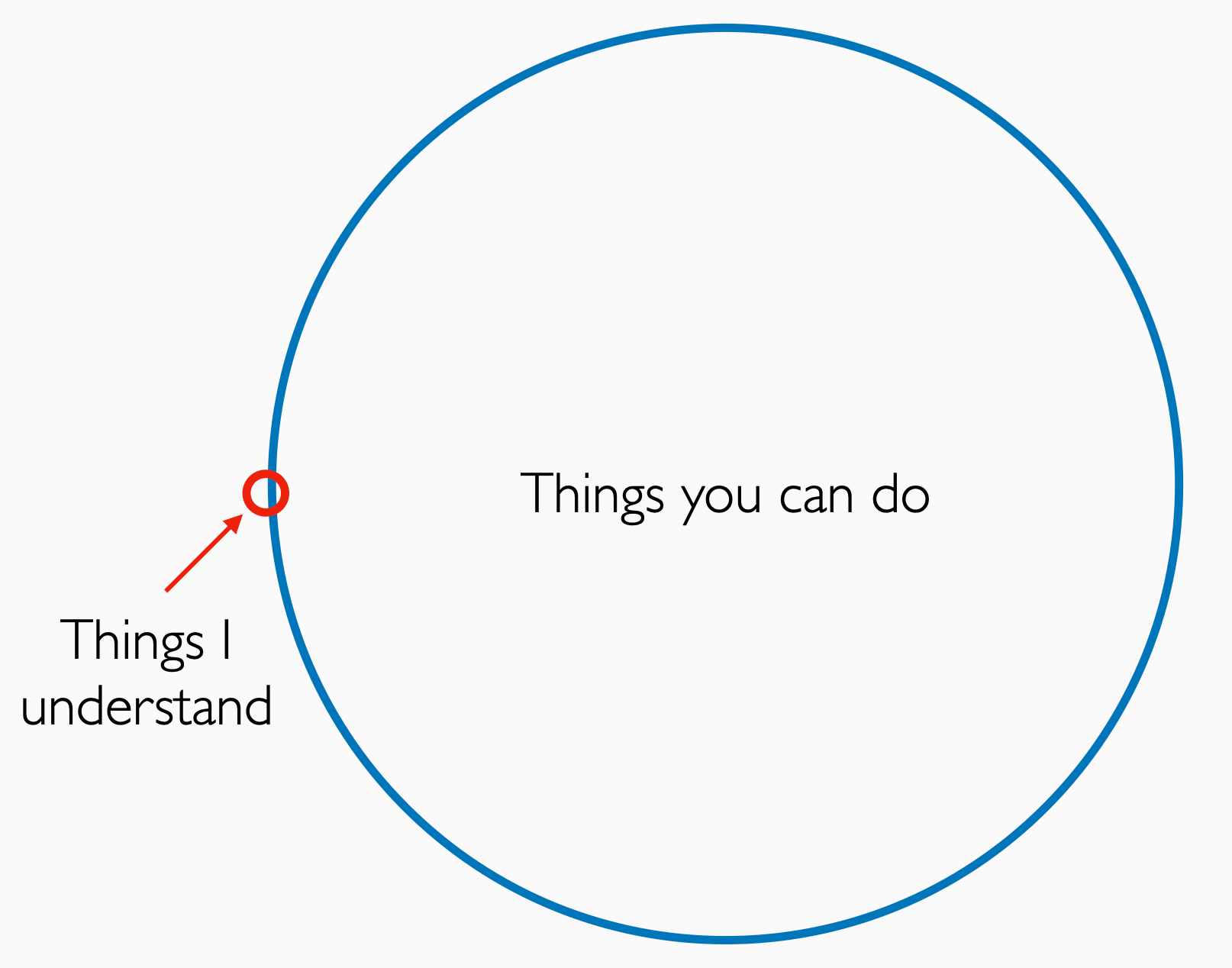
What I describe in this blog is all of the red circle and a little bit of the blue. And that’s the most important takeaway: to push the envelope in machine learning, you have to get yourself into that blue circle while trying to expand the red. To do the mindblowing, you have to work with that which you don’t understand.
> After this, I’m going to write a bit about pedagogy and live-blogging a class. I have thoughts!
I really appreciated it and hope that more instructors follow your example. In some ways it is even more helpful to the world--and perhaps students--than making the videos available.