
Risky Predictions
Meehl's Philosophical Psychology, Lecture 2, Part 3/3.

This post digs into Lecture 2 of Paul Meehl’s course “Philosophical Psychology.” You can watch the video here. Here’s the full table of contents of my blogging through the class.
Putting Popper aside for a moment, Meehl notes a critical property of theories is their ability to predict new facts. Which of the following would be more impressive: that you develop a theory that agrees with facts F1 and F2 and predicts a new fact F3? Or that you find a theory that agrees with F1, F2, and F3.

The two diagrams have the same three facts and the same theory; all that changes is their temporal ordering. Everyone would agree that the first scenario is preferable to the second.
We like theories that predict the future more than theories that only predict the past. As Meehl says, “A theory's ability to predict a new fact is far more important than its ability to explain an old one.” We don’t want scientific theories just for the sake of truth-building. We don’t just want a good agreement with our corpus of facts. We want theories for understanding the unknown. We value their predictive power. We value a theory if it is, again, in Meehl’s words, “remarkably detailed in its predictions and in close accord with the facts.”
“If the logician cannot explain why the working scientist prefers to predict new facts than merely explain old ones, then my current attitude is very high-handed. And I tell him, well, you better go back to the drawing board, buddy.”
But are all predictions equal? Popper, especially later in his writing, says no. He demands theories be put to the “riskiest” tests conceivable. For Popper, theories that pass a series of risky test are corroborated. This means that not only have they not been falsified, but they have not been falsified by tests designed to falsify them.
What counts as a risky test? Meehl argues, “what impresses the scientist is a numerical prediction of a point value or a very narrow range that pans out.” I’ll use this definition today, but Meehl’s notion of risky will expand in the later lectures.
Meehl goes through an example of weather prediction to elaborate on his point. If a theory only predicts it will rain next April, no one will care. But if a theory predicts it will rain exactly on seven days in April in Minneapolis, and this pans out, you might get more invested in the theory. If the theory correctly predicts an exact list of the seven dates and the amounts of rainfall down to the millimeter, you’ll think this theory of weather is potentially revolutionary.
With this example in mind, Meehl defines risky in a clever way: it is the volume of a “target space” made by a prediction. We often know a range of potential observations in advance. IQ has to range between 0 and 200. A person’s height has to be between 0 and 10 feet. It has never rained more than a foot in a day in Minneapolis. Meehl calls the space of all possible observations the Spielraum.1 The Spielraum for IQ is the interval [0,200], for height is the interval [0,10], and for April rain is the 30-dimensional box [0,300]^30.
The narrower the region of the Spielraum in which a theory makes predictions, the more impressive or “surprising it is.” Since the whole point of this concept is used to reflect the surprise of the scientific community, Meehl introduces Bayes’ rule as a way to think about how predictions might “confirm” or “give credence” to a theory (these are now my scare quotes).
Let T denote the theory and O the observed risky prediction. Roughly speaking, we have the probabilistic relationship:
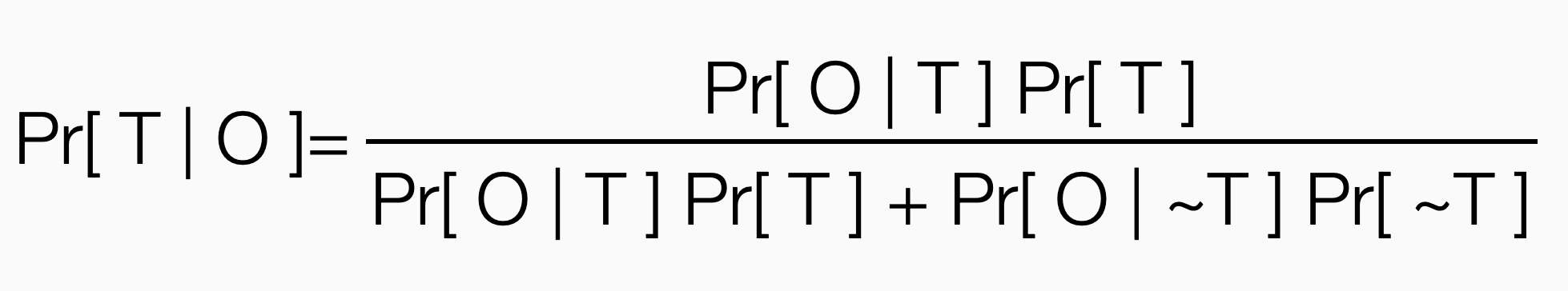
These probabilities are not meant to be actual numbers but to serve as a helpful metaphor. Let’s just talk through what happens here. The condition “not theory” means the world without the theory in question, not a competing theory. If you believe the probability of an observation is very small without the theory, the second term in the denominator is very small. This is where the Spielraum comes in. If the volume of the prediction is tiny, your prediction should feel like random guessing in the absence of your theory. If the likelihood of an observation is tiny without the theory, the ratio of the numerator to the denominator is pretty large. The more risky the prediction, the closer the ratio gets to one. Hence, risky predictions support the theory.
For this reasoning to work, the prior on the theory can’t be too small. The more outlandish the theory, the more risky the evidence required. In this view of corroboration as an application of Bayes’ Rule, you have to apply Sagan’s standard and demand that “extraordinary claims need extraordinary evidence.”
I love the technical term Meehl uses for this sort of theory testing. If your theory predicts a narrow range of the Spielraum, the prediction being accurate is a damn strange coincidence (DSC). DSC is a technical term Meehl attributes to Wesley Salmon, who also promoted using Bayes’ Rule as a philosophical means of confirming theories. The DSC concept will make frequent appearances in the class.
Meehl notes that Popper didn’t believe in this sort of Bayesian thinking. In Popper’s mind, you wanted to test the most improbable theories. Popper would talk about theories with the fewest number of parameters or the fewest potential consequents. It’s riskier to make a prediction with a simple model than a complex one.
It’s, let’s say, a strange coincidence that Salmon and Popper completely disagree about philosophy but get to the same answer. Salmon was an inductivist, and Popper dogmatically denied induction. Salmon believed you could assign probabilities to theories; Popper thought this was mathematically impossible. Salmon talks about support and confirmation; Popper refuses to use those terms. And yet the two ideologically diametric approaches give the same sorts of answers. Meehl says this is reassuring.
Still, over the course of this lecture (and three blog posts) we moved away from pure analytical philosophy to humoring the whims of scientists. All scientists agree that ceteris paribus prediction is a more powerful corroborator of a theory than post hoc explanation. All philosophers of science have acquiesced to this point, but we don’t yet have a clear picture of why. To get some clues, we’ll have to engage even further with the history, sociology, and psychology of science.
Spielraum was an early term used—by Keynes in particular— for a probability space. Meehl uses it a lot, so I’m sticking with his terminology. And the literal translation of “game space” is a cute way to describe potential probabilistic outcomes.
Super interesting post (as always) Professor! I'm curious about the value of P(O | not Theory). How could one begin to conceptualize this value? The set of theories that are not the one being tested in infinitely large — is there an intuitive way to quantify the probability of the observation given that it is in this space?
I’m pretty sure Damn Strange Coincidence refers to getting an outcome in the given narrow range of the Spielraum in a world without the theory T.