
Clinical versus Statistical Prediction (III)
Meehl's Philosophical Psychology, Lecture 10, part 3/3.

This post digs into Lecture 10 of Paul Meehl’s course “Philosophical Psychology.” Technically speaking, this lecture starts at minute 74 of Lecture 9. The video for Lecture 10 is here. Here’s the full table of contents of my blogging through the class.
The earliest study Meehl finds demonstrating the superiority of statistical judgment asked whether “scientific methods” could be applied to parole. In the 1920s, sociologist Ernest Burgess worked with the Illinois Parole Board to determine the factors that contributed to recidivism and whether it was possible to predict whether a parolee would commit further crimes after release.
Burgess assembled 21 predictive factors, including age, the type of offense, whether a person was a repeat offender, and whether the person had held a job before. He then constructed a sophisticated AI tool for predicting parole: he scored each factor either 0 or 1 and then added them all up. Of the 68 men with at least 16 positive factors, only one ever committed a crime again. Of the 25 men with fewer than five positive factors, 19 recidivated.
In a 1928 report, Burgess compared his predictions against two prison psychiatrists. He gathered a dataset of 1000 men who appeared before the Illinois Parole Board in the 1920s. The psychiatrists assigned each prisoner as likely to violate parole, unlikely to violate parole, or uncertain. Of the ones deemed unlikely to violate, the first psychiatrist predicted 85 percent correctly, the second 80 percent. Of the ones deemed likely to violate parole, the first psychiatrist predicted 30 percent correctly, the second 51 percent. Burgess’ method, looking for at least ten positive factors, not only made a prediction for all parolees but correctly predicted 86 percent of the ones unlikely to violate and 51 percent of those likely to violate. It outperformed the first psychiatrist at predicting violations and the second at predicting successful parole.
Algorithmic recidivism prediction remains a contentious topic. It is one of the most popular examples discussed by the machine learning fairness community. The common refrain is to argue that these risk assessments are examples of “an opaque decision-making system that influences the fundamental rights of residents of the US.” But Burgess was attempting to make the case for a more liberal parole system. He thought his algorithm could be less political, more fair, and more accurate.
Meehl highlights a dozen other studies in his book and continued to track these throughout his career. No matter how much he looked, he kept finding the same thing as Burgess: statistical rules were seldom worse and often much better than clinical predictions. In a reflection on his book, Meehl wrote in 1986, “There is no controversy in social science that shows such a large body of qualitatively diverse studies coming out so uniformly in the same direction as this one.”
He may have been right. I wasn’t sure how best to convey the evidence, but let me discuss two meta-analyses from the 21st century. Meehl was no fan of metaanalysis (and neither am I), but sometimes it’s worth gathering all the papers and looking at the trends.
The two biggest, broadest meta-analyses were done by Grove et al. (2000) and Ægistdóttir et al. (2006). Grove et al.’s analysis included 136 predictions. In 46% of the predictions, mechanical methods were roughly 5 percentage points better than clinical judgments.1 That is, the difference between the accuracy of the statistical and clinical predictions was at least 0.05. In 48% the predictions were close to each other within about 5 points of each other. Clinical predictions were substantially better than mechanical predictions in less than 6% of the studies. This plot from Grove demonstrates further that there was a skew in the distribution.

Here, a positive score denotes an advantage for mechanical prediction and a negative score an advantage for clinical. When they were better, mechanical predictions were more frequently far better.
Ægistdóttir et al. focused on statistical methods but found the same results as Grove et al. In their compilation of 48 predictions, 52% favored statistical methods, 38% reported comparable performance, and 10% favored clinical judgment.
What should we make of these findings? First, and foremost, let us realize that we should accept that statistical judgment can be considerably better than expert judgment. This should inform how we proceed in decisionmaking about people. However, I cannot emphasize enough here that just because statistical prediction is never worse and often better than clinical judgment, that doesn’t mean that you still can’t screw up statistical prediction. Careful statistical prediction remains a delicate skill.
You can have too few features.
You can have too many features.
You can have completely uniformative features.
You can have missing data.
You can have non-stationarity and frequency shifts.
These are just a few of the major headaches you have to deal with. If we’re going to rely on statistical prediction, then we need expertise in statistical hygiene.
With regards to that hygiene, I also want to emphasize again and again and again that you shouldn’t just break out some fancy new machine learning method and assume it’s going to be the best method. Many have noted that sophisticated machine learning methods are often outperformed by least squares. But least squares is still statistical prediction! One of Meehl’s examples is Sarbin’s study (1943), which showed a two-variable linear regression based on high school ranking and college entrance exam score was more predictive of a student’s success at the University of Minnesota than the assessment of the university’s clinical councilors. Just because simple ML methods perform better than complex ones does not mean that simple ML methods are inferior to clinical judgment.
Recidivism prediction provides another great example. An infamous ProPublica report highlighted a bizarre, opaque psychometric system, COMPAS, sold by Northpointe to the state of Wisconsin for predicting recidivism. Later analysis showed that COMPAS was no better than simple rules like Sarbin’s. Fancy opaque rules should always be compared to the simplest baselines. For many of these messy social questions, you’ll never beat the simple rules because the prediction problems are so hard anyway.
Statistical rules are more accurate, faster, and cheaper than experts. They can even be more fair and safe. And yet, statistical prediction is not a panacea. Meehl didn’t think so either! Statistical rules need to be targeted at interventions with simple outcomes. They are challenging to keep updated. Tech companies retrain their prediction systems every day. Medical risk assessments might stay static for decades. And mechanical rules have human costs. They can lead to an erosion of expertise as practitioners spend too much time deferring to their apps. They can lead to decision fatigue, forcing too many things into a computerized system. And they can lead to complacency, as following mechanical rules is drudgery. For all these reasons, the adoption of mechanical rules and statistical prediction in high-stakes scenarios must be done with care.
I understand why the power of statistical prediction will remain discomfiting for professionals. Statistical prediction is atheoretical. There’s no good reason why counts of the past lead to reasonable predictions of the future. That’s the problem of induction, my friends. I’m not going to go full neorationalist on you and argue that statistical prediction always works. That would be ridiculous and I don’t believe it (I have written endless blogs on why). We should interpret Meehl as providing us with a setting where statistical is probably going to be better than clinical: answering clear, multiple-choice questions about simple actions from machine-readable data. This characterization is useful!
Still, it feels like a doctor can assess more than what is fed into the computer. That a counselor can see subtle queues that are valuable for prediction. That there are edge cases statistics can’t catch. Isn’t this true? Why is clinical judgment worse on average?
The key to the entire clinical-statistical puzzle is those last two words. “On average.” The trick that Meehl plays–and that all bureaucrats play–is in the quantification of “better.” By better we of course mean on average. Once you decide that things will be evaluated by averages, the game is up. If you believe that prediction is possible, and you tell me that I’m going to be evaluated by hit rates, then I’m going find a method that maximizes hit rate over some class of possible algorithms. In machine learning, we call this empirical risk minimization. You should find a rule that predicts the past well and use this to make predictions about the future. Since you will be evaluated based on averages, this is effectively the optimal thing to do.
Meehl summarizes the situation in the last paragraph of his 1954 book. If we subscribe to the bureaucratic utilitarian mindset, the algorithm always wins:
“If a clinician says, ‘This one is different’ or ‘It’s not like the ones in your table,’ ‘This time I’m surer,’ the obvious question is, ‘Why should we care whether you think this one is different or whether you are surer?’ Again, there is only one rational reply to such a question. We have now to study the success frequency of the clinician’s guesses when he asserts that he feels this way. If we have already done so and found him still behind the hit frequency of the table, we would be well advised to ignore him. Always, we might as well face it, the shadow of the statistician hovers in the background; always the actuary will have the final word.”
As is the case with all meta-analyses, the way they pool their comparisons is frustrating. In order to evaluate the bulk benefit of one method versus another, you have to take a diverse set of results and homogenize them. Both of these studies do this by trying to scale the difference between clinical and statistical judgment to standardized units using Cohen’s d. Specifically, if one method has accuracy a1 and the other method accuracy a2, then
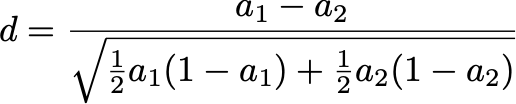
A method was favored if |d| was greater than 0.1. Now, if a2 is 60% and d is 0.1, then a1 is 65%. If a2=70% and d=0.1, then a1=74%. This is why I say “roughly 0.05” above. Is this the right metric? Gah, I don’t think so. But if you have a better idea, please tell me in the comments!
The initial scope conditions are begging the question. From yesterday: "For open-ended questions, Meehl thought clinical expertise was indispensable. It was only for problems with simple multiple-choice answers where he thought statistical decision-making could play a role."
Once we subset to the questions that machines can analyze, then the machines can outperform humans. The myth of John Henry. There's no meaningful way to compare machine prediction against human prediction in cases where machines can't function. But we don't have any way to measure the value of human prediction in these contexts -- if we could measure it, machines could do it better.
Quantitative science requires translating the world into machine language. Progress in statistical prediction comes from expanding the scope of the world that is machine-readable. This is the imperative of the "bureaucratic mindset" of high modernism developed by the state -- and more recently, the inductive "high-tech modernism" developed by tech companies: to simplify humanity in order to govern it.
^ https://direct.mit.edu/daed/article/152/1/225/115009/The-Moral-Economy-of-High-Tech-Modernism
What interests me about this series is that Meehl isn't just an ordinary psychologist, he's a Freudian psychoanalyst (it's of interest of mine—I went from rationalism to psychoanalysis too.) I wonder how he squares it with his analytic work, because psychoanalysis is *the* exemplar of "clinical-first", the analysand has to be treated in her "singularity", her particular history that has to be considered, which is why psychoanalyst sorts make the claim (and rightly so imo) that it doesn't make sense to average the results of psychoanalytic analysands to compare with eg. CBT.
I wonder of course if Meehl's response is that as an analyst he's not in the business of making standardized predictions (and neither can any psychoanalysts I can think of, really)