
Calibrated Games
Solving the game of forecasting with accounting strategies.

This is a live blog of Lecture 8 of my graduate seminar “Feedback, Learning, and Adaptation.” A table of contents is here.
One of the main uses of simulation and forecasting in designed feedback systems is for deciding how to act. If I can map what will happen next, I can choose actions that steer me toward good outcomes. This mindset seems perfectly sensible, and it’s the backbone of statistical decision theory, tree search in game play, optimal control, and model predictive control. Moreover, people who are good at prediction get clout. You can even win money in markets. It seems like forecasting is a skill and talent, and one that requires deep knowledge of how the world works. And yet, in class on Monday, I discussed how you can make excellent forecasts by simple, strategic accounting.
To understand why, let’s examine how we know if forecasts are good. It’s sort of obvious, but we can only evaluate our predictions of the future once the future has become the past. I can’t tell how good your forecast is until the forecast event occurs. No matter how much we think about setting up ungamable metrics, forecasters can only be evaluated retrospectively. And this retrospective nature means we can cast forecasting in the game theoretic framework from last week. Let me write out the rules in the format I’ve been using.
We have a two-player game with repeated interactions. In every round t,
Information xt is revealed to both players.
Player One makes the forecast pt
Player Two takes reveals the actual outcome yt
A score st is assigned based on the triple (xt,pt,yt).
Player One is the “forecaster.” Their goal is to accumulate as high a score as possible, summed across all rounds. Player Two wants the sum of all of the st to be as low as possible.
Now, we need to come up with score functions that can’t be “gamed,” and people have thought of many. For example, you might require the forecaster to have a low Brier score.
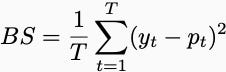
Now, a low Brier score is impossible in the adversarial context. Think about this weird game of bit prediction, where Player One guesses a number 0 or 1 and Player Two responds with the correct answer equal to 0 or 1. Player Two goes second and can always pick the opposite of what Player One says. That seems unfair.
Last week, I brought up the possibility of judging Player One with regret. Regret would measure the difference between Player One’s score and the score of a player who knows all of Player Two’s moves in advance but can only play a single prediction. In math, this quantity is written as
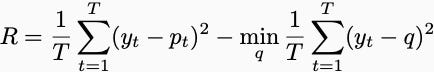
But good predictions alone may not be what you care about. Certainly, you’d want the frequencies to match. If you are predicting a sequence of probabilities, the average of those probabilities should match the average of the actual outcomes. If you consistently predict a player makes 90% of their free throws, we should see 90% of free throws made.
Similarly, other expected values should match. If you are changing your probabilities over time, the variance of the outcomes should still match the variance of your probabilities.
Maybe you’d prefer the predictions to be good across stratifications of the data. For example, if you are predicting free throws, maybe you’d want your forecasts to be accurate for all players individually. There are lots of subtests and subsets I can inspect, and I’d like to check that you are making good predictions on all of them.
Perhaps you’d like a certain degree of calibration from the forecast. In all of Player One’s forecasts where they say 20%, Player Two should say 1 only 20% of the time. In the forecasts where they say 60%, Player Two should say 1 60% of the time. If in all of the times Player One says there’s a 90% chance of a 1, only 10% of the times Player Two plays a 1, we’d think Player One is a pretty bad forecaster. Trying to achieve calibration across all possible probabilistic predictions seems a lot harder than just getting a single frequency correct in a Brier score game.
Mathematically, however, all of these problems are basically the same. They list a set of “test functions”, and Player 1 wants the following to be small for every single test function:
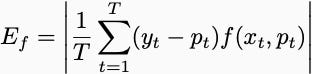
What are the test functions? If all we care about is getting the frequency that yt equals one correct, then the test function is the constant function. For calibration, the test function is equal to one when a forecaster predicts probability x% and 0 otherwise. You’ll have one test function for each calibration bin. For calibration across strata, there will be a function for each stratum. Even Brier scores amount to calibration. You can get a low Brier Score by calibrating the functions
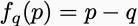
for all values of q.
The amazing thing is that making calibration errors of the form Ef small is incredibly mechanical. Juanky Perdomo and I spell out the general details in Section 3 of the tutorial “In Defense of Defensive Forecasting.” More or less, you just have to choose a prediction that makes the future look uncorrelated with the past. And you can always find such a prediction with simple search. Though there are specific details you have to deal with for each case, essentially the same procedure applies to very general sets of calibration functions.
We found that we could reduce every metric used to evaluate forecasting skill to some form of generalized calibration. There are whole bodies of work on proper scoring rules, conformal prediction, omniprediction, and outcome indistinguishability that reduce to generalized calibration. In the forecasting game, this generalized calibration can be done without specific domain expertise. As long as the evaluation metrics are prescribed in advance, a Defensive Forecaster will do well in fantasy sports, weather prediction, and election forecasting. It doesn’t need to know anything about the topic other than the judgment scheme.
Though Juanky and I wrote up our defense of defensive forecasting almost a year ago, this week was the first time I tried to present it in class. I got a lot of puzzled looks, as if I was playing clever card tricks. That’s the correct reaction! We are naturally impressed by people who are good at forecasting. We’re obsessed with predicting the future. Predictions from soothsayers are reassuring even if they’re consistently wrong.
And yet, forecasting is often just playing clever tricks for fun and profit. Though Dean Foster and Rahesh Vorha famously showed that percentile calibration amounted to bookkeeping thirty years ago, it turns out that all forms of generalized calibration can be achieved through bookkeeping. Next time someone tries to impress you with their prediction market prowess, remember that cooking the books isn’t the same as clairvoyance.
I'm confused. You observe the (trivial) result that you can't possibly get a low Brier score in the adversarial context, but then you go on to observe that you can frame Brier scores as a calibration problem, and that you can always minimize calibration errors with this One Neat Trick. But obviously you can't do that for Brier scores, so there's got to be more assumptions buried in the result (I haven't looked at the paper, I freely admit).
So, I am indeed left feeling a bit like you're trying to pull a fast one...
Could you say a bit more about the compare & contrast with frameworks like outcome indistinguishability by Dwork Kim et al? https://arxiv.org/abs/2011.13426