
An Inversion Cookbook
Modularity lets us pose a zoo of inverse problems as convex optimization problems

This is the second part of the live blog of Lecture 11 of my graduate class “Convex Optimization.” A Table of Contents is here.
This is my first time trying to teach Boyd and Vandenberghe Chapters 6 through 8 in a class, and I’m now realizing each chapter could be a semester. I’m definitely struggling to figure out how to do these surveys in 80 minutes. Yesterday’s linear inverse problems survey was much more rushed than I’d have liked.1
Sleeping on it, I wonder if I should have approached this lecture a bit differently. The spirit of the book is recognizing modeling design patterns and showing how simple building blocks can be fused in surprising ways to tackle a diverse set of problems. Let me do that today for inverse problems, taking a pragmatic look at throwing together convex models of linear inverse problems.
Recall from yesterday that the buy-in requires assuming a linear forward model from the state of the world to measurement. In notation, y is the measurement, x is the state of the world, and w is the noise. We assume “y=Ax+w” for some linear transformation A. We pose problems today where we are always solving for x and w at the same time. Those are our decision variables.
Linearity is a big assumption but is a good approximation with unreasonable frequency. Moreover, if you can get by with a linear model, you are guaranteed a tractable optimal solution to your inverse problem. Sometimes that tradeoff is worth it!
I’ll stick to two implausibility functions: sum of squares and sum of absolute values. Yes, the first is a squared norm and the second a norm. There’s all sorts of fun theory and geometry you can extract from those facts. But to build practical optimization models for inverse problems, the norm stuff doesn’t matter. I had considered writing the functions “𝜎” for the sum of squares and “𝛼” for the sum of absolute values, but I worried this would just confuse everyone. To keep the exposition clear, I’m going to write sum of squares and sum of absolute values as norms today, but I want to emphasize this is purely for notation. Keep that in mind as we see what problems we can pose with these two penalties.
OLS. Ah, ordinary least squares. Everyone’s favorite way to lie with data. In this case, we assume we’d be able to find x if it weren’t for some exogenous noise w. This suggests we should minimize the size of the noise that is consistent with the measurements. We penalize the sum of the squares of the noise because we don’t have any preferred direction in which the noise might point. I’ll refer to this as a “white noise” assumption today. The associated optimization model is
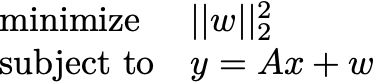
You can solve this one in closed form.
Robust regression. Suppose that you think the noise might be a combination of two signals, a white noise signal and a sparse signal with high amplitude. Or perhaps you think that some of the measurements are “outliers” and should be thrown away entirely. We could penalize the sparse and white noises separately as in this model:

This works really well! For my robust statistics folks out there, this optimization problem is equivalent to using the Huber loss function in regression. The parameter 𝝀 is a hyperparameter that you have to tune to balance the outliers from the rest of the noise. I’ll use 𝝀 freely below as a parameter you’ll have to set by modeling.
Ridge Regression. Ridge regression is useful for high dimensional regression problems where even when w is small, there are many choices for the state estimate x. In this case, we can now penalize the sum of squares of the state too, yielding a problem

This one is also nice because it can be solved in closed form.
LASSO. In many problems, we’d expect the state itself to be a sparse vector. In this case, we can penalize the sum of the absolute values of the state. This gives us a problem commonly called LASSO regression:

Anything goes. We really start cooking with gas once we allow ourselves to penalize weighted combinations of absolute values and squares. Let’s consider the general problem where we introduce two weighting matrices T and U and solve the optimization problem:

If T and U are both the identity matrices, this is called elastic net regression. If T and U are diagonal matrices, this formulation lets you weigh different components of the state differently, encouraging some coefficients to be small and some to be large. For example, suppose that the coefficients of x correspond to frequencies in a signal decomposition. Then maybe you’d add higher weights to higher frequencies to emphasize their implausibility.
Non-diagonal weights are also helpful. If you introduce finite differencing operations, you can penalize signals with large variations. For example, consider the matrix that looks at the difference between neighboring components:

Penalizing the sum of the absolute values of this matrix times x is akin to preferring an x with sparse derivative, i.e., a piecewise constant function. You can also penalize an approximation of the second derivative using the finite differencing matrix

Penalizing the sum of squares of the 2nd derivative encourages smooth models. These penalties even suggest the denoising problem, where we have a signal x corrupted by noise (so that A is the identity matrix):

Here we have a lot of noise, but a strong prior on what the state can be. When T=0, this problem can be solved in closed form, multiplying x by a matrix. This matrix “filters” the measurement to remove the noise from the state.
There are infinite possibilities here, and I’m not going to exhaust them in a blog post. All I can do is give you a taste of the rich, modular toolbox that convex optimization brings to the study of linear inverse problems.
Apologies to everyone in lecture if that felt too much like drinking from a firehose. Ask me questions here if any of it was too confusing or if there were other modeling problems you had hoped I would cover.
Just a quick question. Huber loss is differentiable, but the above formulation you relate Huber loss with is not?
Wow this is really cool. I work on dictionary learning a lot and people put all sorts of constraint on x. I am in particular interested in hierarchical dictionary learning. And do you know if people in the field of inverse problem deal with some of hierarchical problem as well? For example, in the last part where you introduces a weighing matrix T. Isn't this kind of introduces a "second layer"? Like how you measure y with A result in x. Now you measure x with T, result in another variable, let’s call it z, s.t. x = T^{-1} z. Can set some additional constraint on the second layer variable z? like ||z||_1? This will be similar to the inference in hierarchical dictionary learning for multi-scale signal like imaging. And is it still convex?