
Theorem: Chance Equals Fate
Missing data induces statistics without probabilty

Yesterday, I argued that in bit prediction–at least philosophically–we got to the same prediction strategies whether modeled data as randomly sampled iid or deterministic. What determined our algorithms and analysis was how we scored prediction error. The scoring implicitly posed the prediction problem as a missing data problem. Today, I’ll back this up with math instead of philosophy. You can pick your poison.
With missing data problems, a clairvoyant agent who knows the values of the missing data can compute the best prediction ahead of time. We score prediction as the average error over all of the bits. In a formula, if {yt} is your sequence of bits, and p is your prediction, your score is
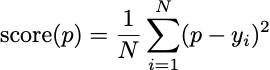
The optimal prediction in this case is evident: it’s the mean of all of the bits:

The error of this prediction is

That is, the optimal score is the variance of the bit stream. This identity sets the ceiling for our algorithms.
You have to make a constant prediction because you think the bits are all equally important and effectively indistinguishable. A constant prediction necessarily makes some mistakes even if you see all the bits in advance. The best error achievable depends on how close the stream is to being a constant.
Now let’s suppose the bits are actually generated by the iid model. Each bit is independently sampled from the same probability distribution. Once we have a probabilistic model we can equate our expectations of our predictions with mathematical expected values. Let’s denote the mean of the first t bits as mt. If we use the first t, to predict the last N-t, we find that the error on the remainder is

In this case, we have that the error on the tail of the sequence is equal to the expected error on the next bit, which is equal to this expression that is only slightly larger than what you would have predicted if you knew all of the bits in advance.
What about the deterministic model? In our iid model, we had
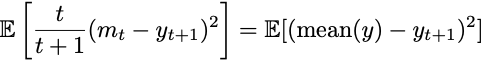
That is, up to a small scaling factor, using the first t bits to predict the next bit is, on average, the same as using the true distribution mean to predict the next bit. It turns out this is true without making any random assumptions. The following identity is true for any sequence of real numbers:

You can check that this is deterministically true by doing some algebra or trying a bunch of cases in python or asking o1 or whatever. It says that with appropriate weighting derived from the iid model, predicting the next bit from the first bits accrues the same error as predicting the mean of all of the bits. Using the past to predict the future has the same mean-squared error as using all of history.
I stumbled on this identity because I was reading a bunch of papers by folks who work on online learning, trying to make sense of the math of bit prediction. Indeed, you can derive the identity I wrote here by copying the proof of the regret bound for strongly convex online gradient descent by Hazan et al., being careful not to note that many of their inequalities can be considered equalities in bit prediction. Nothing I’m writing here is new, and I’d bet someone like David Blackwell already knew the identity I wrote above decades ago.
This identity shows us that it’s the averageness doing the heavy lifting in bit prediction. On average, a step ahead predictor is as good as a predictor that sees all of the answers in advance. We just needed to ensure (a) the rules stated that you had to make the same prediction for all of these bits, and (b) whatever predictions you make, they have no effect on the bit sequence. Casting the problem in this way determined the best achievable score and the best algorithm to achieve it. The data models were a consequence of the evaluation criteria.
The scoring system is asserting that nothing distinguishes one bit from the other. Even if you see all the data, scoring average error produces a stationary policy. Once you tell me all bits are indistinguishable, I can’t do better than making the same prediction for every bit. The salient issue isn’t randomness versus determinism. It’s the notion that our evaluation scores the future and the past.
That said, the iid calculations are considerably simpler than the deterministic ones. So, I’m probably going to stick with the iid model for the rest of the semester. It’s probably good enough to make progress even though it’s decidedly unnecessary and unverifiable. I will note every time I mention it that iid doesn’t really mean random. The iid assumption is just shorthand for marking when events are philosophically indistinguishable. In machine learning and statistical prediction, probability is merely a convenient superstition that simplifies calculations.
Things get trickier once the world responds to our evaluations. We’ll have to grapple with this later in the semester, but at least we have a starting point.
FYI the deterministic identity you derived is a special case of Theorem 1 in https://arxiv.org/pdf/1112.1390 for the one dimensional case with constant covariates equal to 1 and taking the limit of "a" to 0. So, a similar equality holds more generally when you use online ridge regression. You also have the very same equality between marginal likelihood and predictive distributions in Gaussian Processes.
Great post and cool identity.
An awkward bit is to explain "(a) the rules stated that you had to make the same prediction for all of these bits" when you really employ an online rule that does make evolving predictions.
I personally find the assumption of exchangeability to be a pretty intuitive match for "all missing outcomes are indistinguishable from each other -- both apriori and conditioned on anything you've seen so far." Online learning papers tend to acts like this is true, but shy away from stating it outright.