


The Technical Depths of Crud
Meehl's Philosophical Psychology, Lecture 7, part 1.

This post digs into Lecture 7 of Paul Meehl’s course “Philosophical Psychology.” You can watch the video here. Here’s the full table of contents of my blogging through the class.
Meehl begins Lecture 7 by clarifying his rant about statistics from Lecture 6: “I love statisticians, and I like statistics.” It’s certainly true that Meehl should not be confused as someone who is against statistical methodology. Lectures 6 through 10 are almost entirely about probability and statistics, after all. And after his five-minute quasi-apology to the “subgroup of statisticians who have a certain arrogance toward the social or medical sciences,” he spends the next 45 minutes of Lecture 7 diving into numerical examples of how the crud factor might manifest itself even when theories are false.
In the spirit of these technical calculations, let me take this post to work through a few mathy-ish loose ends on crud. There will be more equations than have been the norm in these blog posts, but that’s because we’re pushing into arguments with statisticians. I’m setting the stage here for the subsequent posts where I want to try to rethink statistical practices with crud in mind.
Thresholded Variables
Meehl works an extended example where the treatment variable is a thresholded normal. A potential example he gives would be groups that score high on a test versus groups that score low on a test. Perhaps you’d look at the mean of some attribute in people above the mean on an introversion scale and compare that to the mean of people low on the scale. If the introversion scale is a normal distribution, then the treatment variable is a thresholded normal distribution.
The correlation coefficients between thresholded normal random variables are close to those of the unthresholded variables. There are lots of fun integrals you can compute. Let θ denote the Heaviside function: θ(t) equals 1 if t is greater than 0 and equals 0 otherwise. If X and Y are normally distributed, then:
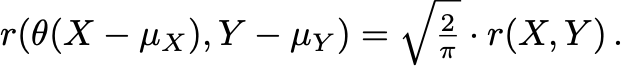
If you threshold one variable, the resulting correlation equals 0.8 of the initial correlation. Meehl alludes to this formula in his whiteboard calculations in Lecture 7. We can go a step further and threshold both X and Y:

If X and Y are correlated, their thresholded counterparts will be similarly correlated. Thresholding normal distributions does not eliminate the worry about crud.
Epidemiological Crud
I don’t exactly know how to best estimate the modern crud factor, but I think it’s worth giving some scale. In Monday’s post, I called out this JAMA Internal Medicine article that claimed people who ate organic diets had lower cancer rates. We all know these nutrition papers are absurd and easy to pick on. And yet they still consistently get credulously written up in the New York Times. This paper doesn’t seem to be any more egregious than any other in the field. The whole field is very bad! But it does help give a sense of scale.
In this paper, the authors come up with some score of how much organic food people eat. They find the top quartile of scorers have low cancer rates. Obviously, this is clearly a dressed up correlation with wealth and socioeconomic status. Bear with me anyway.
In their main finding, they have 50,914 with low organic score and 16,962 with high organic score. Of these survey respondents, 1,071 of the low-organic group reported cancer while only 269 of the high organic group reported cancer. That’s a 25% relative risk reduction. While it’s not proper to treat this as an RCT, the z-score here is more than 4 and the p-value is less than 0.0001. So I could imagine (as the paper does) some sort of “causal correction” mumbo jumbo that “corrects for confounders” or whatever and still gets you a p-value less than 0.05. Eat organic, everyone!
OK, so what’s the correlation coefficient? We have a formula for it. Take the z-score and divide it by 261. It’s about 0.02.
I don’t yet know what to make of this. The fact that cancer is already rare means the correlation coefficient can only be so high. For binary random variables when the treatment and control groups are of the same size, the largest the correlation coefficient can be is the square root of the odds of the prevalence:
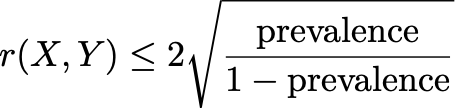
This would be the correlation between X and Y even when you have 100% risk reduction. It would be worth thinking more about what Meehl’s crud has to do with epidemiology where we have huge n and low prevalence, and hence all variables with small correlation. What is the crud factor in epidemiology? Somebody should study that!
Varied Variance Estimators
Dean Eckles noted on Twitter that for non-binary outcomes, the common estimator for the variance in the z-test is a combination of the variance in the group when X=0 and the group when X=1:

I could quibble that this variance estimator isn’t better than the one used in the proportions z-test, but it’s a quibble. As I’ve said before and will say again, these formulas are just rituals and you can’t really justify anything with “rigor.” And it’s fine because we can still calculate stuff. If I use this variance estimator, the formula for z becomes

Carlos Cinelli tells me that Cohen uses this formula in his writings about power and effect sizes. While it is no longer a simple product, nothing in the crud story changes here. A significance test is still computing a simple function of the Pearson r, multiplying that number by the square root of n, and declaring significance when that product is larger than 2. That is the same as declaring significance when

That 4 in the denominator isn’t doing much work. Also, when r is less than ½, this z-score is less than 1.15 times larger than when you use the other variance estimator. We can’t escape the fact that significance tests are measurements of correlation. Maybe we should embrace that fact and see what happens.
On the point of how large of a correlation you get get when prevalence is low, you might be interested in concepts like "switch relative risk" https://arxiv.org/abs/2106.06316v1
If you allow arbitrary nonlinear transformations of the covariates, then it seems like the crud factor is nicely captured by the maximal correlation, see e.g. https://www.jstor.org/stable/2242042. This, of course, does not resolve any of the epistemological or methodological issues.