
The Central Path
The brilliant simplicity of primal-dual interior point methods.

This is the live blog of Lecture 19 of my graduate class “Convex Optimization.” A Table of Contents is here.
How do we jump from unconstrained optimization to constrained optimization? In unconstrained optimization, we are free to follow any direction downhill, so we can let simple local search run without worrying. In constrained optimization, we require a solution matching a specification. How do we ensure local search finds such a point?
There are many methods, and the next couple of weeks will explore several. We’re going to skip the convergence proofs in this class. Our goal is to understand the mechanics of how these algorithms work so that we can tune our models to match what these methods are best suited for.
I want to start with a class of algorithms that sounds the most intimidating but is in many ways the most simple: primal-dual interior point methods. Optimality conditions for convex problems are almost always a set of equations and inequality constraints. Primal-dual interior point methods solve the equations with a damped Newton method, where the step size is chosen so that the inequality constraints remain valid for all iterations.
Suppose we want to solve a nonlinear equation F(x)=0, where F is maps n-vectors to n-vectors. We additionally impose the restriction that our solution lies in a convex set C. For a simple motivating example, let’s say we want to solve the system

A valid solution is x=0, y=-1. Another is x=1, y=0. What if we want an algorithm guaranteed to find the solution where x and y are nonnegative? This is a typical constraint in interior point methods.
Interior point methods thus seed Newton’s method with a candidate point in the set C and then take damped Newton steps constrained to always lie in C. The meta-algorithm is
start with x in the interior of C
while norm(F(x)) is large:
compute the Netwon direction v at x
find a large step size t such that x+tv is in the interior of C
set x to x+tvThis algorithm is aptly dubbed an interior point method because it always maintains an iterate in the interior of C.
The primal-dual part of the algorithm comes in when we are solving the optimality conditions of a convex optimization problem. In this case, the equations we aim to solve are the equalities from the KKT conditions, and the convex set C is the set of tuples of primal feasible and dual feasible points. Let me now turn to a concrete optimization problem to make this explicit.
We have been studying the general constrained optimization problem
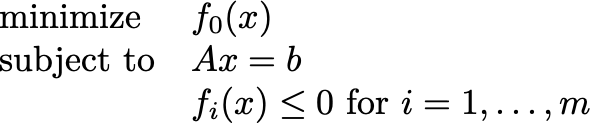
Let’s fix that the primal variable is n-dimensional, and there are m inequality contractions and p equality constraints. The KKT conditions are

Here, s and 𝝀 are the dual variables, aka the Lagrange multipliers. The first three lines here are, as promised, equations. The total number of equations is n+p+m. There are n primal variables and p+m Lagrange multipliers. Aha, we have a square nonlinear system. The convex set C is

We can use our meta-interior point method to solve this problem. We first find a candidate x that strictly satisfies the inequality constraints. We also initialize the variable s to a positive vector. Then we take damped Newton steps, ensuring the iterates stay inside C.
The only hitch to making this work is guaranteeing that we can take large step sizes. This is the sticking point in all of the convergence analyses. The problem is that the KKT conditions demand that the optimal solution lie on the boundary of C. As you get close to that boundary, the algorithm will have a hard time making progress.
The main brilliant fix, inspired by a decade of working on interior point methods, is to take Newton steps on a relaxed set of equations.
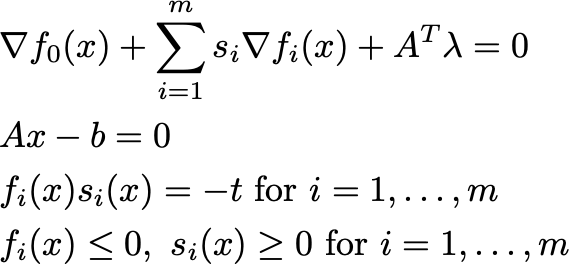
These are the same as the KKT conditions, except that we enforce the product of the f_i(x) and s_i to be equal to the positive scalar t. Namely, their product must equal -t. This can only happen if the solution is well inside the interior of C. For convex problems, every value of t defines a unique point in C. As t goes to 0, these points converge to the optimal solution of the optimization problem. The path of solutions to these modified KKT conditions is called the central path.
Targeting the central path gives interior point methods more wiggle room to take larger steps. Keeping iterates close to the central path guarantees convergence of the primal-dual interior point method. This works astonishingly well in practice. There are simple rules for how to make t smaller as you progress so that the step sizes remain reasonable as you approach the boundary. Since Newton’s converges quadratically near optimality, you can adjust the path parameter to take advantage of this fast convergence and push your iterates to complementary slackness.
The details of how to make these things precisely work in practice aren’t too hard. I highly recommend Steve Wright’s book Primal-Dual Interior-Point Methods for the gory details. Steve also gave a fantastic tutorial on these methods at the Simons Institute. Though it’s been more trendy as of late to always run first-order methods, hand coding up an implementation of the primal-dual interior point method isn’t hard. It’s even easier if you use automatic differentiation tools. For modestly sized problems where matrix inversion is feasible, these methods are hard to beat.
Thanks so much for the post. I have very limited knowledge in this topic; but, I was very much impressed with Karmarkar's algorithm Especially, the description here https://ise.ncsu.edu/wp-content/uploads/sites/9/2021/07/LPchapter-6.pdf is very good. If anyone happens to know the source of this .pdf, please let me know. (I am guessing that other chapters are also good.)