
The Art of Deconstraining
A guide to convex optimization in Pytorch.

This is the second live blog of Lecture 20 of my graduate class “Convex Optimization.” A Table of Contents is here.
DSLs like cvxpy and solvers like MOSEK are amazing for rapid prototyping and can carry you very far. However, you’ll often get stuck by commercial solver limitations as you scale to larger data or need to accelerate run-time because of production demands. Eventually, all optimizers need to roll their own solvers.
Having done this before, I can attest that writing a custom primal-dual interior point method is much easier than it sounds. The basic iterations just require structured solutions of linear systems. The outer loop is based upon scheduling your trajectory along the central path, and I’ve found Mehrota’s Predictor Corrector algorithm robust, efficient, and easy to implement for this task.
However, we’re in the age of LLMs, and no one likes to solve linear systems anymore. Instead, they want something you can Pytorch. Pytorching usually means that we need to transform our constrained problem into an unconstrained problem so that we can just autodiff our way to glory. It’s not obvious, but a revisionist reading of Boyd and Vandenberghe tells you how to do this.
First, how do you get rid of equality constraints? Suppose you want to enforce Ax=b, where A is p x n. Most deep learners tend to make equality constraints into regularized penalties. They add a term ||Ax-b||^2 to your cost function, and with an appropriate weighting, you can get this small.
But there’s a way to just completely eliminate the constraint. The key is to note that if u is any solution of Ax=b and F is a matrix whose columns span the null space of A, then
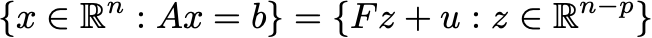
This means that solving the constrained optimization problem

is equivalent to solving the unconstrained optimization problem
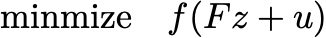
for the variable z. The price of admission for this transformation is computing the matrix F. You can do this with a singular value decomposition. This is an expensive operation (the SVD costs O(p^2 n + n^2)), but it’s a one-time cost before optimizing, and you can gradient descent to your heart’s content after that.
What about those inequality constraints? If you want to force h(x) to be less than or equal to zero, you could add a penalty function max(h(x), 0) to your cost. If you penalize this enough, it should force your solver to find a solution where h(x) equals zero. This is the exact penalty function method. It’s not the worst idea in the world, though characterizing when exactly it works is delicate, even for convex problems.
Another idea is to approximate a convex indicator function. Let I(s) be the function that is equal to infinity for negative s and 0 for nonnegative s. This is the convex indicator function of the nonnegative numbers. Then minimizing

is equivalent to the unconstrained problem
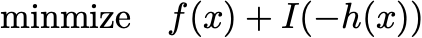
The problem here is that if you have a point where h(x) is greater than zero, the cost is infinite and you don’t get gradient information. If you have a starting point where h(x) is less than zero, then the penalty term is zero, and you’d have to implement some sort of procedure to ensure that your gradient steps never leave the constraint set.
A way around this conundrum is to approximate the indicator function with a smooth function. The canonical approximation is

for some positive scalar t. This logarithmic approximation has the feature that for s larger than exp(-t), the penalty function is less than 1. For smaller s, the function diverges to infinity. This divergence is helpful for optimization. If you start at a feasible point, a descent method will have a hard time taking you out of the feasible region.
What would it mean to minimize this approximation? You’ll find a solution with h(x) bounded away from zero. If you successively solve this problem by making t progressively larger, then h(x) is allowed to push towards zero. With an appropriate schedule for t, you’ll find a good approximation of your original problem. This is called a barrier method and is a kind of interior point method. Nothing says you need to solve this barrier method with Netwon steps. If you want to run ADAM or whatever you kids are into these days, go to town!
The problem with optimization algorithms is Anything Goes. Yes, for a large class of convex problems, the primal dual interior point methods are guaranteed to run in polynomial time. But there are other choices, and sometimes you throw out guarantees for heuristics better suited to your computing constraints. Optimization algorithms are a toolbox. Sometimes the specialized tools are simply not well suited for the job at hand. It’s good to have choices because sometimes the wrong tool is right for your problem. For convex problems, it’s worth giving the PDIPM a shot. But in the age of Pytorch, know that there are lots of other things you can try if the so-called optimal methods don’t work for you.
Thanks for the insightful post.
From what I understand, the log barrier formulation is typically solved using Newton’s method. At least, the B&V textbook only mentions Newton’s method in this context. I wonder if this is because the log barrier can make the augmented objective severely ill-conditioned, causing first-order methods to struggle. While this may not be a major issue if feasibility is prioritized over optimality, I am still curious about how first-order methods might perform in practice in this setting.