
Membership Checks and Short Proofs
Slouching our way to duality theory

This is the live blog of Lecture 8 of my graduate class “Convex Optimization.” A Table of Contents is here.
The two central concepts of constrained optimization are feasibility and optimality. A point is feasible if it satisfies all of the constraints. A point is optimal if it is feasible and its objective value is less than or equal to the objective value of all other feasible points. To check if a point is feasible, you evaluate each constraint and verify that it holds. This is almost always a straightforward numerical procedure based on a few primitives (e.g., Is some function less than zero? Is the vector nonnegative? Is a matrix positive semidefinite?).
Checking optimality is trickier because of the associated logic. Feasibility is a “there exists” problem. You can check feasibility by plugging in values to an appropriate formula. Optimality is a “for all” problem.
Feasibility:
There exists an x that satisfies the constraints and has f(x) less than or equal to t.
Optimality:
For all x that satisfy the constraints, f(x) is greater than or equal to t.
How can you check that a point has a lower objective value than every other? For a function to be verifiably optimal, we need a “short proof” of optimality. We need to be able to plug something into a formula that proves optimality. In convex optimization, we turn optimality checking into feasibility problems.
The transformation is very subtle. The first thing to note is that a function is locally optimal for a convex optimization problem if the directional derivative is positive in all directions that could stay feasible. For if the directional derivative were negative in some direction, you could move your point a small amount and decrease the function value. A point is optimal if all such decreasing moves leave the feasible region.
For convex sets, the set of all feasible directions is a cone (if two directions move a point inside a convex set, their sum and scaling do too). I’ll call it the feasible cone. Here’s a nice picture of some feasible cones:

The grey shading indicates the directions that can stay feasible. In the left picture, any direction in a half space can move inside the circle. On the left, only a restricted set of directions can stay inside the polygon.
Everyone forgets this from multivariate calculus, but the directional derivative of f in the direction v has a formula. It is the dot product of v with the gradient of f:

Rederive this for yourself! We want this dot product to be nonnegative for all v in the feasible cone. That means we have stumbled on a bizarre geometric fact. Verifying if x is optimal for a convex problem is thus transformed into if the gradient of the objective is in the dual of the feasible cone at x:

Fancy! We went from some simplistic geometric arguments to checking membership in a dual cone. But it is sort of neat: we transformed a “for all” problem into a “there exists” problem. If we can compute the dual cone of the feasible set, optimality checking is no harder than feasibility checking. This is only true for convex problems and is again a reason why we spend so much time on them.
For the circle above, the feasible cone is a single vector. It’s saying that the gradient of f must point along the x-axis. Here’s a picture showing the dual of the feasible cone for that polygon:

The cone is slightly wider than the polygon itself.
As is always the case in this class, we move back and forth between geometric intuition and algebraic verification. We can explore a few instances of what this condition means algebraically.
Unconstrained problems
For unconstrained problems, every direction is feasible. This means the dual cone is the point 0. That is, a point minimizes a convex function over Rn if and only if its gradient is equal to zero. I am sure many of you have seen that condition before. At least this extra algebraic geometry is recovering common sense.
Equality constrained problems
When does x minimize f over the set where Ax=b? It turns out that this is true if and only if there exists a v such that
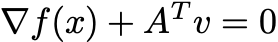
This v is called a Lagrange multiplier. We’ll have a lot more to say about these on Thursday.
Nonnegatively constraints
What about minimizing functions over nonnegative vectors? The optimality conditions here start to look a bit more exotic. x minimizes f over the nonnegative vectors if and only if the gradient itself is a nonnegative vector, the gradient is equal to zero in the components where x is nonzero, and x is equal to zero in the components where the gradient is nonzero. There is, let’s say, a complementarity between where the gradient vector is zero and the x vector is zero. Think about this condition in 2d:
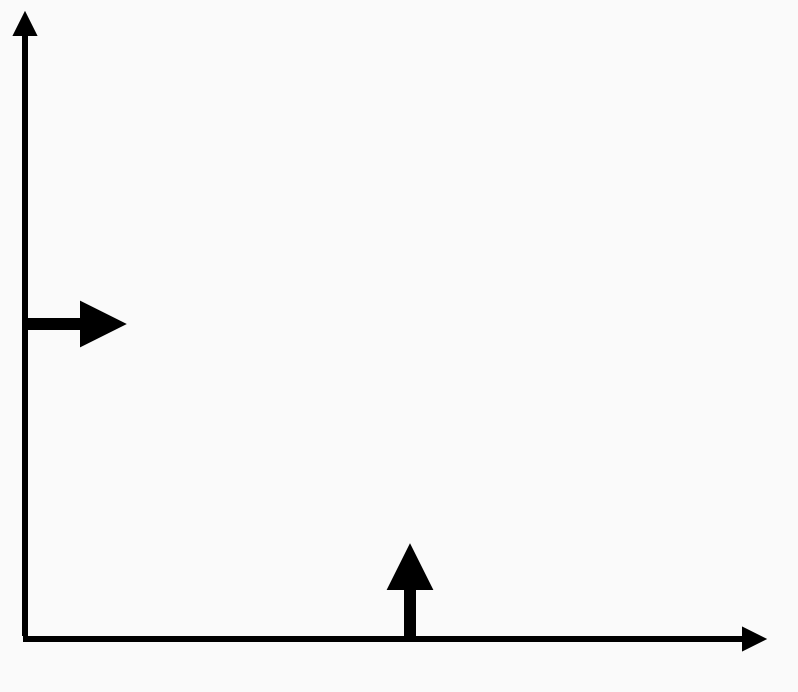
On the boundary of the orthant, the only way to move into the set is to be orthogonal to that particular axis.
Now, if we had to derive optimality conditions on a case-by-case basis for all possible constraint sets, we wouldn’t be able to solve anything. On Thursday, we’ll dive into a systematic way to generate these sorts of optimality conditions: convex programming duality. The two ideas here, complementarity and Lagrange multipliers, will form the basis.
[by associative memory I'm reminded of our discussion* about falsification and the "forall" vs "exists" type of logical sentences from the previous argmin season. If only one could solve all scientific problems by convex optimization...]
* here: https://open.substack.com/pub/argmin/p/popperian-falsification?r=2k6f6v&utm_campaign=comment-list-share-cta&utm_medium=web&comments=true&commentId=54704131