
Look before you leap
Good decisions are based on good measurements

If you only want to act when the unknown condition is true, we can associate decision-making under uncertainty with hypothesis testing. There were four possible outcomes of binary actions with binary conditions, and we can label them as follows.
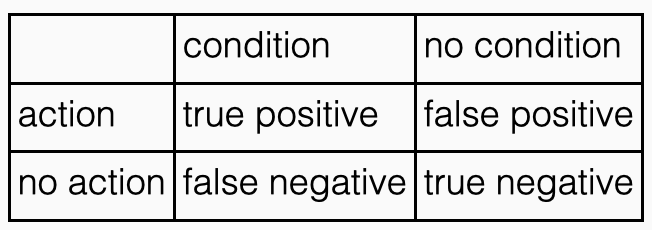
The expected reward associated with a policy is a balance between the true positive rate (TPR) of the policy and the false positive rate (FPR) of the policy. The TPR is the fraction of the time that the policy predicts the condition is true when the condition is true. The FPR is the fraction of the time that the policy predicts the condition is false when the condition is true.
TPR and FPR are fundamental in statistical testing problems and go by so many different names. TPR is also called power, sensitivity, probability of detection, and recall. It is equal to one minus the false positive rate, which is the same as the infamous Type II error and the probability of missed detection. FPR is the associated Type I error. FPR is also called size or probability of false detection. And the 1-FPR is known as specificity. I never remember what any of these terms mean and always have to look them up. I curse whoever came up with naming error types by Roman numerals. But in any event, these concepts are important! And balancing these error types is equivalent to policy optimization.
Perhaps it’s worth an equation to verify this equivalence. Let p denote the probability that the unknown condition is true. (p is called our prior on the condition). Then expanding our definition of expected reward yields the following relationship:
I put this equation in because it shows that any problem that tries to balance TPR against FPR is equivalent to a reward maximization problem. This also means that all such problems are solved using the algorithm we developed yesterday, where we compared odds against a cost-benefit threshold.
In hypothesis testing, this algorithm is called a likelihood ratio test. Statistics books more commonly write the test as:
if p(x|y=1)/p(x|y=0) > threshold
take action
else:
don't take actionThis algorithm is exactly equivalent to the one we derived yesterday. It just uses the definition of conditional probability to swap p(y|x) for p(x|y). This probability p(x|y) is called the likelihood. It’s the likelihood of the data under an assumption about the condition.
For our reward maximization problem, we have a formula for the threshold in the likelihood ratio test
But now we can ask what happens as we turn the knob on that threshold. Every value of that threshold will have an associated TPR and FPR. (An associated pair of Type I and Type II errors, an associated pair of sensitivity and specificity, etc, etc.). If the threshold is zero, we always choose action, and hence the TPR is one. But, the FPR is also 1 in this case. If the threshold is set to infinity, we never act, and the TPR is zero. But now the FPR is also zero. In the intermediate ranges, we get some other values. The set of all possible FPRs and TPRs for likelihood ratio tests traces out the ROC curve. ROC stands for receiver operator characteristic, a term that comes from characterizing radar systems during World War II. Here’s what an ROC curve might look like:

Now, you might ask, for some tolerated FPR, what is the best possible TPR you could get? Can we get a TPR higher than we saw in the likelihood ratio test? One of the most famous results of statistics, called the Neyman Pearson Lemma, says that the answer is no. The ROC curve of the likelihood ratio test tells you the best possible TPR given that you are willing to accept a certain fraction of false positives.
ROC curves are funny beasts. These things have some value, but they get waaaaay overblown in machine learning and data science. First the good. The likelihood is a probabilistic characterization of a measurement. In the radar case, the likelihood was summarizing how much noise was in the receiver. By making the radar signal stronger, the noise went down. Correspondingly, the signal-to-noise ratio (SNR) went up. Better receivers would have ROC curves closer to the plot's upper left corner. That’s where we aspire to be!

If only we could all be as prescient as that purple curve.
Sometimes, people like to compare different likelihood models by the area under the ROC curves. This sort of captures the desire to push the curve up to the left. But this is a funny metric that we shouldn’t obsess about. We have to remember that we only ever care about a single point on this curve. Our design specification almost always includes an acceptable level for FPR. So here are two ROC curves with equal area under them.

But if you care about small FPR, then you would choose the blue one. They aren’t equal once you specify the FPR.
People have come up with all sorts of justifications for caring about the area under the ROC curve (perhaps it tells you about the ranking of positives versus negatives), but, again, you only ever care about one point in practice. This bizarre obsession with areas under curves has gotten most egregiously distorted in medical papers. People use area under the curve to brag about how their dumb new deep learning algorithm achieves superhuman performance. Every time I see such an argument, I scream at my laptop. My laptop is likely suffering from PTSD. Look, humans do not have ROC curves. Every person is going to be a single point on that plot. While they all strive to be so skilled that they sit at the upper left corner, there is no such thing as the area under the ROC curve of a person.
But I digress. We love ROC curves because they tell us about the limits of noisy measurements. There is only so much statistical wizardry can do if the signal you care about is drowning in noise. If you are not satisfied with the quality of your decisions, you’re best bet is to design a better measurement.
Maybe I'm not understanding what you mean here but there definitely is an area under the ROC curve of a person (or radiologist or whatever you are interested in). You can push around people's decisions by communicating to them different base rates or costs/rewards of errors/correct responses and can also trace out ROC curves by asking them to give confidence ratings (where each rating corresponds to a point on the ROC curve). These are frequently studied in psychophysics and in medical decision making.
This thing has so many names. It is called hypothesis testing in detection theory, and it is called contingency table in game theory, or just Pascal's wager. But in its essence, isn't it just one step stochastic dynamic programming?