
Linear Doesn't Mean Easy
Applied linear algebra is much harder than advertised.

This is the second part of the live blog of Lecture 5 of my graduate class “Convex Optimization.” A Table of Contents is here.
I had slated a bit of time at the beginning of Thursday’s class to work through a few examples of how to prove functions were convex. But this ended up consuming the entire lecture. I always forget that every first-year grad class needs to fit in at least one stealth tutorial on linear algebra.
It was true for my cohort, and it’s still true now: everyone who comes to engineering research needs to take a class to understand how engineers think about linear algebra. For me, this was Detection and Estimation with Greg Wornell. For you, maybe it’s Convex Optimization with me. Regardless, it takes a lot of practice to get a feel for applying linear algebra. It requires a sophistication with algebra, geometry, and analysis, and sometimes it takes doing it a dozen times before it really sinks in.
Some facts are underappreciated and taxing. Linear algebra is noncommutative (AB is usually not equal to BA), so a lot of the intuitions you get from solving polynomial equations in high school go out the window. None of the formulas simplify the way they should. Linear equations like AX + XAT = Q don’t have clean, interpretable solutions. Eigenvalues are weird, and you need to see a dozen examples of their applications before you appreciate why professors are so obsessed with them. Singular values are more important than eigenvalues, yet almost no one really learns what a singular value means in college. You can sort of do algebra on matrices. A2 makes sense. For positive definite matrices, A1/2, the square root of A, is well-defined. However, the properties of these algebraic expressions don’t match our intuition from high school algebra.
In addition to Boyd and Vandenberghe’s books, one of the most magical PDFs I received in graduate school was a set of notes on linear algebra assembled by Tom Minka in 2000 (thanks to Ali Rahimi for sharing these magic tricks). Tom put together a bunch of facts that he thought were useful for statistics. The formulas contained therein are so esoteric and confusing that I still have to open this PDF on a regular basis. Let me give a crazy example.
The determinant is one of the more esoteric formulas we encounter in linear algebra. For a positive definite matrix, the determinant is just the product of the eigenvalues of the matrix. The determinant can be used to calculate ellipsoidal volumes, the entropy of probability distributions, and designs for experiments. Though a useful modeling tool, it’s also not a function we’d ever want to compute by hand for matrices with more than three rows and columns.
It turns out that the determinant is log-concave on the cone of positive definite matrices. That’s a wild fact. Why is it log-concave? Boyd and Vandenberghe have a short proof that uses the fact that convex functions are convex if and only if they are convex when restricted to lines. But the steps in the proof are pretty confusing if you don’t have linear algebra tricks at your fingertips. It definitely led to a lot of confusion in class yesterday! We needed to know that the determinant is a multiplicative homomorphism (det(AB) = det(A)det(B)), that every positive definite matrix has a square root, and that adding a multiple of the identity to a symmetric matrix adds that multiple to eigenvalues. For a first-year grad student, this is a wildly disparate set of facts. Linking the necessary linear algebraic patterns together takes a course or two to get straight.
Another way to prove the log-concavity of the determinant is to compute the Hessian. But this approach also takes us in weird directions! The Hessian has to be a matrix, but the inputs to the functions are n x n matrices. That means the Hessian is an n2 x n2 matrix. Tom computes this in equation 107 in his note:
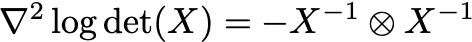
A tensor product? Yikes. There is something perpetually unintuitive about derivatives of matrix objects. I suppose this sort of feels right because the second derivative of the logarithm is -1/x^2. However, I’m guessing almost no one sees Kronecker products in undergraduate linear algebra.
If you believe the formula, this proves that the log determinant is concave. Since X is positive definite, its inverse is positive definite. The tensor product of two positive definite matrices is also positive definite. This then means the Hessian is negative definite, and the function is hence proven concave.
If that discussion doesn’t feel satisfying, don’t fret too much. I was a math major in college, and I came into graduate school knowing what tensor products were, what eigenvalues were, and what determinants were. Nonetheless, it still took me a couple of years of work to internalize computational linear algebra. There’s an underappreciated art to it that you learn the more you do optimization, statistics, or signal processing.
Now, a question in our age of LLMs is do you need to know this? If you are going to do innovative research, the answer is decidedly yes. Deep neural networks have nothing to do with the brain. They have everything to do with pushing around derivatives of functions of tensors. If you want to understand what neural nets do and how to make them better, you need intuition for the matrix analysis under the hood.
The fun part of neural networks is the promise that no one has to understand linear algebra. You just have to be able to call an automatic differentiator and tweak some existing model, and you get a conference paper or push a feature to production. Automatic differentiation tools exist so you never have to compute derivatives anymore. Maybe you don’t need to think about eigenvalues and determinants and such. Maybe you can just pytorch pipette your way to papers. That’s possible. But if we choose this path, what do we lose?
Derivatives in terms of Kronecker products is a bad idea. I say this after reading Magnus/Nuedecker and using their notation for a couple of years. Turning everything into a matrix adds a "flattening" step, and your formulas will be different depending on whether you use row-vec or col-vec operator to flatten. Math convention is col-vec, but GPU tensor layout is row-vec, so you end up with "wrong order" formulas propagating into slow implementations (ie, in https://github.com/tensorflow/kfac) . Alternative is to keep the indices. Derivative w.r.t. matrix variable has 2 indices. Hessian has 4 indices. If you don't want to come up with index names, can use graphical notation as in https://github.com/thomasahle/tensorgrad
I can completely relate to this as I am teaching convex optimization this semester. I was proving the concavity of logdet the other day. Everyone was completely lost even math students.
After teaching convex optimization over the past four years, I have identified a trend: students background in linear algebra is getting worse every year; and they are more inclined to know the end application before caring about the foundations.
This course is getting more and more challenging to teach! Would appreciate your suggestions.