
Information Transit Got the Wrong Man
The mechanized tradition of peer review and the absurdity of bureaucratic conference review.

In case you hadn’t heard, people are using LLMs to create their peer reviews. I know, you’re as shocked as I am. To their credit, the program committee of the International Conference on Machine Learning (ICML) has been doing things to address the problem. Their attempts reveal the systematic problems here that are unfixable without a dramatic teardown.
Let’s recap the situation, though even typing it out makes me feel like a character in a Terry Gilliam movie.
In November 2025, the PC sent a series of surveys to past ICML reviewers to gauge their sentiment about LLMs in reviewing. They assumed that this list must also include a bunch of authors because they mandated a reciprocal reviewing policy for the 2025 conference, under which all submissions must have had at least one author who agreed to serve as a reviewer. In their final survey, they proposed the following policies for LLM reviewing at future conferences, and asked for preferences:
Policy A (Conservative): Use of LLMs for reviewing is strictly prohibited.
Policy B (Permissive): Reviewers may input the submission text into privacy-compliant LLMs. However, the assessment of the paper and the writing of the review must not be delegated to LLMs.
A random sample of 500 reviewers received the survey. 74 (15%) answered it. And the survey says!
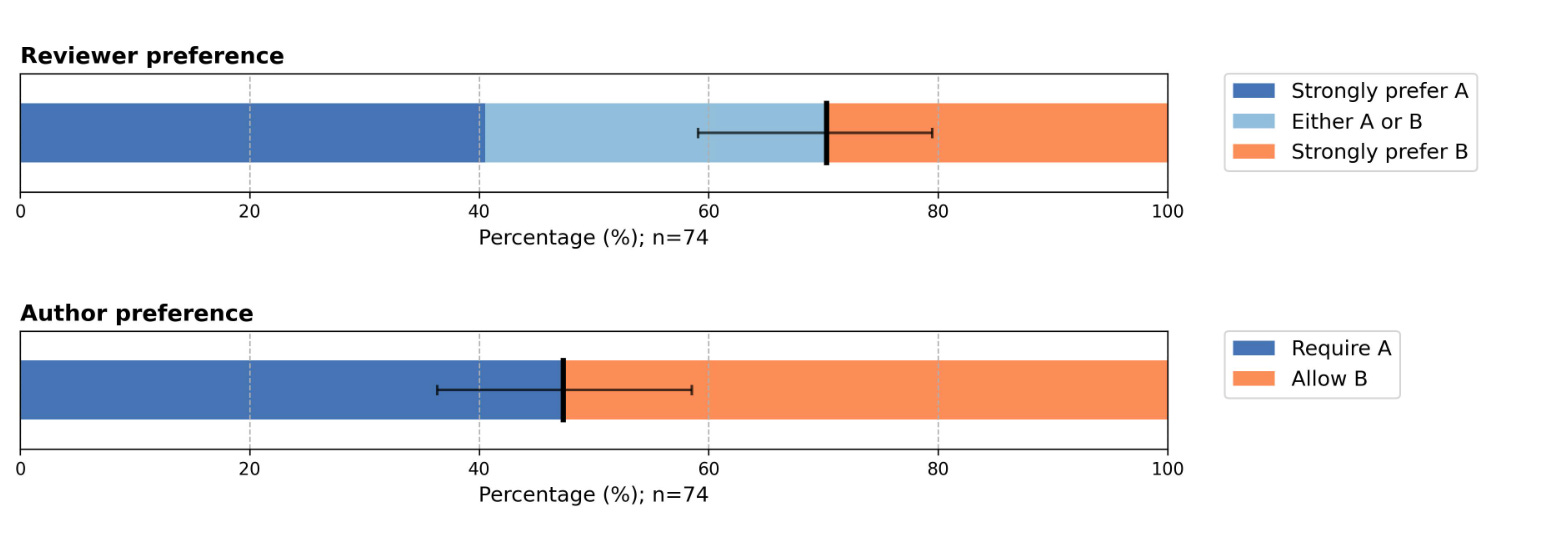
This plot uses default matplotlib colors, so it must be science. I’m not sure what this measures, but whatever, surveys are the democratic way to make policy, amirite? Since the results weren’t equivocal, they decided to make both policy options available in 2026. That’s democracy.
In the multistage reviewer enrollment process for the 2026 conference, they gave reviewers the option of adhering to either Policy A or Policy B or saying they didn’t care. The people who didn’t care were then assigned to one of the two policies in one of the many absurdly long emails they send you when you participate in these conferences.1
Now here’s where it gets weird. The program committee decided to run a sting operation, watermarking the PDFs to trap people who uploaded them directly into LLMs. You can read about their ornate sting operation here. The details are boring. What’s interesting is their response. If they found that someone assigned to Policy A used LLMs in reviewing, then they rejected all papers of which that person was an author. They had 800 reviews that they flagged as violating policy A. They checked every one of these by hand to avoid false positives. Every. Single. One. Because that’s a good use of human manual labor. They ultimately rejected 500 papers associated with these naughty reviewers.
Everyone is patting themselves on the back about this, and tut-tutting those horrible people who dared violate the sacred random assignment of policy, and thanking the committee for their cleverness and transparency. But come on, this whole thing is absurd. The PC argues:
“We hope that by taking strong action against violations of agreed-upon policy we will remind the community that as our field changes rapidly the thing we must protect most actively is our trust in each other. If we cannot adapt our systems in a setting based in trust, we will find that they soon become outdated and meaningless. “
I’m sorry, but it’s already meaningless! ICML received over 33000 submissions. A random subset of 20-25% of these will be approved as “papers acceptable to go on one’s CV.” The process will churn forward. Everyone who attends the conference knows this process is impossibly bad, but the only proposed solutions make the paper-generation process more onerous for humans. This naturally leads people to offload work to LLMs. Next year, people will use watermark detection before they put the LLM into ChatGPT. The wheels of progress will continue rolling.
It’s unfortunate that the natural bureaucratic editorial mode is to assume everyone is cheating and to go on witch hunts to claim progress. The board wrote:
“Conferences must adapt, creating rules and policies to handle the new normal, and taking disciplinary action against those who break the rules and violate the trust that we all place in the review process. “
Psychology took this sort of approach in the 2010s. Though we all got to revel in the high-profile fraud schadenfreude, the field did not come out better for it.
Rejecting 800 of 33000 papers because of possibly inappropriate LLM use, when your LLM use policy is based on the most bizarre, arbitrary decision-making built upon a semblance of objective quantitative social science, is farce. At this point, the AI reviewing process can be nothing but farce. As Kevin Baker succinctly put it in his authoritatively inflectional essay on AI for science:
Systems can persist in dysfunction indefinitely, and absurdity is not self-correcting.
One nice thing about LLMs is that they show us which parts of our systems of intellect are mechanical traditions. LLMs are a good way to stress-test our systems for organizing experience and expertise. We’ll need to be more creative about what we want to do moving forward.
Moving forward requires us to talk more about the point of peer review. Yes, the AI conferences are the most absurd manifestation of this problem, but don’t think that your community is insulated from rampant LLM reviewing. At the Cultural AI conference, Mel Andrews showed us dozens of headlines across academia advocating for LLM review. Arguing that LLM review was better than human review. There are economists launching startups to do this as a service.
Andrews argued that the arguments in favor of LLM reviewing consistently conflated institutional and epistemic concerns. The institutional concerns are well known to us. Reviewing is an enormous burden of unpaid labor that further enriches rent-seeking publication houses, and reviewership is unfairly distributed across academia. The epistemic concerns worry that peer review doesn’t properly weed out invalid papers. At least in the sciences, peer review is supposedly meta-epistemic, judging the validity of papers that aim to get at scientific knowledge, understanding, and explanation. Many studies have found the current state of peer review unfit for this task.
Advocates for LLM peer review argue it solves both problems. Andrews took a hard line, claiming that it can’t solve the epistemic problems. Andrews’ boldest claim is that the relationship of the text generated by LLMs to semantic content and truth is always accidental or incidental. Hence, the mechanical aspects of peer review can only increase confabulation and error. Following tradition means not having to think, but peer review’s epistemic function demands thinking.
I don’t fully endorse Mel’s argument, but it’s a position worth airing and engaging with. By focusing solely on process and rules, tweaks to peer review make it more mechanical. Mechanization only makes LLMs better suited for the job. If epistemic cultivation of expertise and experience demands something beyond tradition, then more complex systems of checks and balances only stifle it.
Program committees in computer science used to be small groups of people who met in person to discuss every paper that would be presented at a conference. They are now ministries of truth that haruspicate the statistics of poorly designed surveys and build ornate policies for the masses. Program committees have become bureaucrats of the state, and they are forced to see like it. The bureaucratization of academic work product threatens its very epistemic nature. Perhaps the fix has to arise from spontaneous order.
Here’s an email I received this morning asking me to be an area chair for one of the other big conferences, NeuRIPS. My AI detector flagged this email as “highly likely AI generated.”
With 33000 submissions, they need to reject roughly 24000. If one rule rejects 800, they need just 30 disjoint rules to do it. That's a much simpler mechanism than a PC, assuming the rules and their number change annually to accommodate the authors learning curve and the number of submissions. Random rules hitting 800 would be nearly disjoint.
For several years now, I have enjoyed this blog and hearing from Ben. I've always enjoyed it when he does the "old man screaming from the mountain" schtick. However, as a young researcher who began working in ML during my master's in India a few years ago, I can't help but feel broken. NeurIPS/ICML are treated as high honours, the highest bar to cross even now here (In NeurIPS 2025, ~10 papers were selected from research done in Indian academia), because we do not have the luxury of making a farm of GPUs that suck up the power of a small town go brrrr.
I have been taught by people I consider researchers of very high caliber, who say that it doesn't get better than this if you want to do rigorous machine learning research that treads the boundary between technical contribution and real-world impact (whatever that means). Sure, old men up mountains scream, "It wasn't like the old days", but that's just what they do. But when Ben says,
> I'm sorry, but it's already meaningless! ICML received over 33000 submissions. A random subset of 20-25% of these will be approved as "papers acceptable to go on one's CV." The process will churn forward. Everyone who attends the conference knows this process is impossibly bad...
I can't help but feel broken. For people who scrape by with little to no resources, and especially for people like me who just got here, I can't help but feel like the door is being slammed shut in our faces. Not by the "old men up mountains", but by what seem to be seedy bureaucrats who exploit the system to ensure that the ever-lengthening death march into the San Francisco startup economy has prompters to churn through.
If it really is a lottery, how can we ever feel like our work matters when we are constrained to a small sample size of submissions? And if "the Ministry is very scrupulous about following up and eradicating any error," then the price of entry seems to be access to incredible resources and the "correct" academic 'network'.
I can't help but feel like the party was ruined before we got there.
Emails are now written by LLMs, responses are written by LLMs, papers are written by LLMs, reviews are written by LLMs, and decisions are made by LLMs.
[This comment was not written by an LLM. My apologies for this rather long comment that may sound like a childish attempt at venting frustration. Do feel free to ignore it. If you have got this far, thanks?]