
Cosma Shalizi Is Aware of All Internet Traditions
Shalizi’s frame of artificial intelligence as mechanized tradition

I’ve been wanting to write a summary of the Cultural AI conference I attended at NYU last week, but I’ve been struggling to succinctly capture my thoughts. That’s indicative of the depth and complexity of how AI meets culture, and the different perspectives and disciplines might not lend themselves to a tidy summary.1 As I often do when trying to wrap my head around complex things, I will stop worrying and just blog through it.
The talk that serves as my hub in the complex network of cultural AI is Cosma Shalizi’s “Aware of All Internet Traditions: Large Language Models as Information Retrieval and Synthesis.” That language models simultaneously retrieve information and synthesize new content isn’t controversial. Nor is the fact that this synthesis is formulaic. The current synthesis is next-token prediction trained on all written information, whose output is warped by some selective post-training. By design, language models mechanistically reproduce the recurring regularities in their training data. That training data consists of all the text files on the internet and what is easily available in printed books. Hence, the regularities are the tropes, stereotypes, templates, conventions, and genres of language and code.
The formulaic generation of discourse looks like discourse in ways we could never have imagined. But with hindsight, we shouldn’t be surprised. Human culture is very formulaic! There are long-standing formulas for oral tradition, for generating small talk, or for generating scientific papers. As Cosma put it, in the single sentence that summarizes the entire Cultural AI conference:2
Following a tradition means not having to think for oneself.
Not having to think is often a good thing! Tradition lets us externalize certain processes so we can focus on other tasks. Formalities strengthen cultural connections. Traditions in communication help us understand each other better and come to consensus faster.
Indeed, our vast externalized cultural intelligence is the jewel of human tradition. Cosma cites Jacques Barzun’s conception of the House of Intellect: intellect is the communal form of society’s intelligence. “[I]t is intelligence stored up and made into habits of discipline, signs and symbols of meaning, chains of reasoning and spurs to emotion — a shorthand and a wireless by which the mind can skip connectives, recognize ability, and communicate truth.” According to Barzun, intellect lets society share and externalize knowledge. It belongs to society, not any individual. It connects individual intelligences. It lives after any single intelligence dies.
GenAI is the mechanization of this intellect. It is the mechanization of all of our traditions.
With James Evans, Henry Farrell, and Alison Gopnik, Cosma has been preaching the gospel that AI is a cultural technology for several years. He’s gone through several iterations of what that means and what it implies, but mechanized tradition is the characterization that resonates most with me. Mechanized tradition of Barzun’s artificial intellect is a far better description of GenAI technology than “artificial intelligence.” This frame helps us get away from the silly C-suite sci-fi navel-gazing about the personalities inside the data centers. Claude is not a person. It is a mechanized intellect. A Lore Laundering Machine. The frame of mechanized tradition helps me build a social metascience of our LLM condition.
Let me give you a fun example.
In the same session as Cosma, Wouter Haverals gave a rhizomatic inspection of the tradition of literary style. What is style anyway? We love to ask LLMs to write in new styles. It’s funny to have it generate poetry. One of my most common queries is how to rewrite emails to sound less angry.
But humans are also great at mimicking style. It can be a fun, creative game to do the sort of rewriting we now task AI with. And our audience can all tell when something hits or misses the mark when we very ape a particular tradition.
Wouter introduced Raymond Queneau’s Exercices de Style, a book consisting of 99 rewritings of the same story in different styles. The main story is simple enough. Here’s Barbara Wright’s 1958 translation:
In the S bus, in the rush hour. A chap of about 26, felt hat with a cord instead of a ribbon, neck too long, as if someone’s been having a tug-of-war with it. People getting off. The chap in question gets annoyed with one of the men standing next to him. He accuses him of jostling him every time anyone goes past. A snivelling tone which is meant to be aggressive. When he sees a vacant seat he throws himself on to it.
Two hours later, I meet him in the Cour de Rome, in front of the gare Saint-Lazare. He’s with a friend who’s saying: You ought to get an extra button put on your overcoat.” He shows him where (at the lapels) and why.
Queneau rewrites this story in the past and the present. In reported speech. In the passive voice. In haiku.
Summer S long neck
plait hat toes abuse retreat
station button friend
Obviously, you can feed an LLM Queneau’s original story and prompt it to write in each of the prescribed styles. Can LLM capture the style? How could you know that LLM did a good job?
The only way to answer such questions is to lean on the tradition of vulgar positivism. In a delightfully recursive metanarrative,3 Wouter and his co-author Meredith Martin ran a survey experiment. On the platform Prolific, they asked “real people” a series of questions about Wright’s translations of Queneau’s original stories and AI-generated versions. They ran several variants. In one, mimicking the style of Kevin Roose’s mechanistically obnoxious New York Times quiz last week, they didn’t tell the participants how the two stories were generated and simply asked which better captured the style. In the second variant, they asked which captured the style better when the participants knew whether the story was Queneau’s or AI’s. In the third experiment, they asked for preferences with the true labels switched.
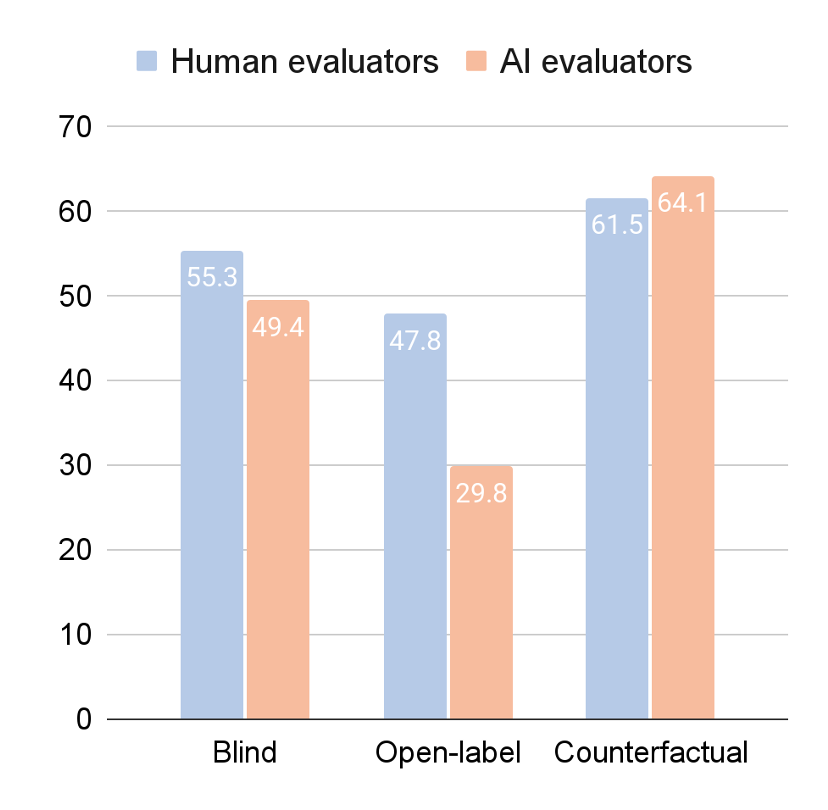
What happened next was entirely predictable. Without attribution of authorship, the “people” on Prolific slightly preferred the AI version, choosing the AI 55% of the time. There were 186 participants and 930 pairwise judgments, so statistical tradition would spew out a confidence interval somewhere between 3 and 7 percentage points wide, depending on the pedantry of Reviewer 2. Make of that what you will. On the other hand, with the correct labels, “people” only chose the AI 48% of the time. Most hilariously, when the labels were swapped, “people” chose what they thought was human 62% of the time.
To situate these numbers within our broader house of intellectual tradition, Haverals and Martin adopted a recently instituted social-scientific tradition: silicon sampling. They ran a survey experiment where the participants were LLMs. When prompted with the same survey, LLMs chose AI-writing 50% of the time without labels. But with the correct labels, the machines judged Queneau superior 70% of the time. And with the swapped labels, AI chose what was presented as Queneau 64% of the time. As the title of Wouter and Meredith’s paper says, “Everyone prefers human writers, even AI.”
There’s nothing surprising in these survey results, and that shouldn’t be surprising. Survey experiments are a woefully limited way to understand the social condition. They are completely mechanical. Of course, this sort of impoverished social science can be done by mechanical literary analysis. Silicon-sampled survey experiments enable us to mechanically generate stories from illusory correlations. These stories are interpreted traditionally as either informative or absurd, depending on the academic tradition in which you were raised. The recursion continues indefinitely. There are so many patterns and regularities in human behavior, and by simulating common text strings, we get text conforming to these regularities. To rephrase Nelson Goodman, regularities are where you find them, and in human tradition, you find them everywhere.
That said, Maxim Raginsky gave a fun synthesis talk on assemblage, feedback, and cybernetics at the end of the conference. I hope he writes up his expletive-laden thoughts on The Art of Realizable.
I wrote Cosma asking whether that quote was a Shalizi-ism or if I was misattributing it. He replied, “It’s not a conscious quotation on my part, but wouldn’t it be better if it was?”
This blogpost is all recursive metanarrative.
Appreciate you taking a moment to write up your thoughts. I'm torn between disappointment and relief that there do not seem to be any poorly made video recordings of the proceedings. I'm landing on relief and expect that my own imagination, along with some working papers and blogposts, is better than muffled voices on YouTube.
And thanks for sharing that Barzun quote. I rather like Brad DeLong's "anthology intelligence" or Shalizi’s own "collective cognition" but now I'll finally go read House of Intellect.
"Mechanized tradition" is a nifty way of characterizing AI. I myself slightly prefer Harry Collins' framework of "behavior-specific actions" because it is a little more precise. LLMs turn text processing into a behavior specific action which is both a genuine innovation but also turns the textual exchange into a mechanical interaction.