
7 Minute Opts
Optimization for Machine Learning In 1000 Words or Less.

This is a live blog of Lecture 4 (part 1 of 2) of my graduate machine learning class “Patterns, Predictions, and Actions.” A Table of Contents for this series is here.
At the tutorials for the 2013 “Big Data” program at the Simons Institute, Steve Wright and I threw together “Optimization for Data Analysis in 90 minutes.” This was one of the most fun talks I’ve ever given. My perspectives on optimization for machine learning have changed in the intervening decade, and tomorrow I’ll write a more skeptical view of its role. But to present the criticism, I first have to present the earnest take. And I still really like this story, even if it’s naive.
Also, I like the challenge of explaining optimization for machine learning in 1000 words with zero equations. Can I do it? Let’s find out.
Why optimize?
In motivating machine learning, I made a plausible case for optimization. To make predictions about new data, perhaps it would suffice to find prediction functions that minimized mistakes on the data we had at hand. Though there were many options, a potential solution was minimizing the average error on our data set subject to constraints on the prediction function. The average error on the data set is formally called the empirical risk. This optimization problem is called Empirical Risk Minimization (ERM).
For the sake of this blog, let me constrain the set of prediction functions in a particular way. I will assume that your prediction function has a bunch of tunable knobs. The goal will be to twiddle the knobs until the empirical risk is as small as you’d like. These knobs could be the weights in a linear expansion like in the Perceptron. These knobs could be more complex components inside a neural network. These knobs could be the literal knobs on a big modular synthesizer that I will tweak to find the perfect sound. It doesn’t really matter. We just need something we can tune so that we can start to make the empirical risk smaller. Our goal is to find the knob setting with the smallest empirical risk.
Gradient Descent
Let’s say I start with a candidate prediction function and want to see if there’s another function nearby with a smaller empirical risk. How might I twiddle the knobs to find lower risk? This, my friends, is why we require everyone to take calculus.
In first year calc, you learned that the direction that induces the largest change in a function is the gradient. You can compute the gradient using all of those wonderful identities you memorized in calculus. Or, I suppose, you could ask Wolfram Alpha. Either way. If you move a little bit along the negative gradient, the function decreases. If the gradient is equal to zero, it is impossible to improve from your current knob setting using small perturbations.
So this reminiscence on Calc 101 suggests an algorithm!
Compute the gradient of the empirical risk with respect to your current knob setting.
Move the knobs slightly in the direction of the negative gradient.
Repeat the process until the empirical risk or the gradient is too small to be worth updating.
This algorithm will stop eventually. If you manage to get your empirical risk to zero, you have found a global minimum of the problem. If your gradient gets to be too small, you can’t say much other than your algorithm has terminated. But that’s fine, because you are in a better configuration than where you started.
Gradient Descent seems like a good method. But to run it, we need our empirical risk to be differentiable. Let’s now make this happen.
Surrogate Losses
In classification problems, we evaluate the average error by counting mistakes. But these counting functions are decidedly not differentiable. Think about the function equal to 1 on the positive numbers and 0 on the negative numbers. There is no derivative at 0. Machine learners compensate by using surrogate losses that approximate these counting functions. The most common approach is to pick a surrogate loss that upper bounds the non-differentiable error function.
Let me give a few examples. Suppose we want to predict data in two classes like in the Perceptron. We label each data point with a +1 if it’s in one class and a -1 if it’s in the other class. A mistake would be if the sign of the prediction differed from the sign of the label. That is, it’s equal to 0 if the product of the label and the prediction is positive and equal to 1 if the product of the label and the prediction is negative. Below are three examples upper bounding this mistake function, from Chapter 5 of PPA:
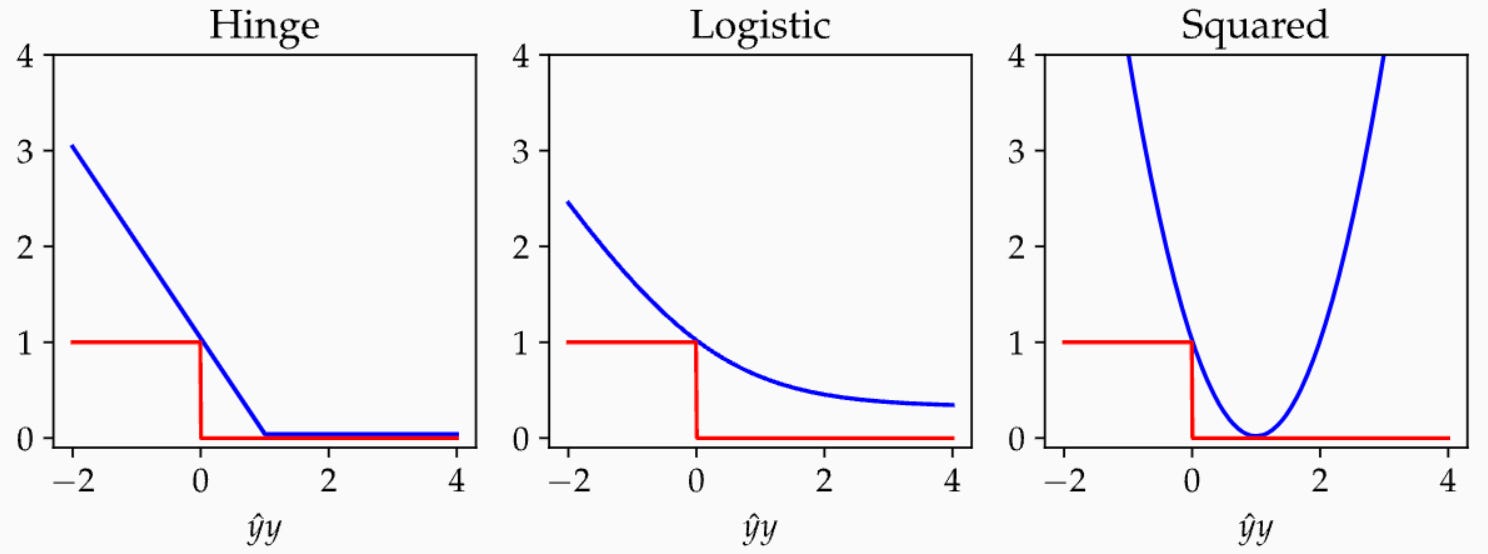
Which one of these should you use? I’m of the opinion that it doesn’t matter. You could invent another surrogate loss if it made you feel good. Other constraints on hardware or software might influence your choice of surrogate loss function. I bring this up only to note that when we stick to a particular algorithm (gradient-esque methods), then you have to mold your machine learning problem to be amenable to the algorithm. Though I wish it were otherwise, most machine learning modeling is based on convenience, not foundational principles.
Stochastic Gradient Descent
Alright, one more step, and we’re done. The empirical risk is the sum of errors made on every data point you have observed. If I have BIG DATA, then maybe I don’t want to look at every data point every time I make a gradient update.
There is a trick that lets us make more efficient updates while not sacrificing too much convergence speed.
Everything rests on the crucial observation you also learned in first year calculus: the derivative of a sum of functions is the sum of the derivatives of each function. This means that the gradient of the empirical risk is then the average of the gradient of the risk of every data point. And this leads to a clever idea: on average, the gradient computed at a random example points in the direction of the gradient of the empirical risk. The gradient at a random example is a “noisy” version of the gradient. This motivates the following final algorithm:
Pick a random data point.
Compute the gradient of the surrogate loss of this current data point with respect to your current knob setting.
Move the knobs slightly in the negative direction of this gradient.
Repeat the process until the ICLR deadline.
This algorithm was named Stochastic Gradient Descent by Leon Bottou in the 1980s. It’s not really a descent algorithm because you can’t guarantee that improving the value of one data point improves the average loss on the entire data set. But you can imagine that this eventually moves in the right direction. You are only going to have large knob changes when the current example is misclassified. And it looks a lot like the Perceptron algorithm we discussed last week.
All the large machine learning models these days are optimized in this fashion.
We’re not empirical risk minimizers after all
There are other algorithms for minimizing empirical risk, and I’ll discuss some of these tomorrow. But we shouldn’t fret about optimization nuances. The dirty secret of machine learning is that we don’t actually solve empirical risk minimization problems at all. Tomorrow, I’ll explain how we use ERM as a subroutine in a more complex and challenging optimization problem.